slatejs实践
简介
Slate.js 是一个完全可定制的的富文本编辑器,准确来说是一个框架。其诞生于 2016 年,作者是 Ian Storm Taylor。它和 Draft.js, Prosemirror, Quill类似,都是基于结构化对象来渲染富文本内容。
slate.js 架构设计类似于 MVC:
(Model)slate 定义了一套数据模型以及更新 model 的一系列 commonds。(View)slate 定义了一套与数据模型对应的视图模型(洋葱模型),使用 react 将数据模型渲染成视图模型。(Ctrl)slate 支持自定义事件监听,然后通过 commonds 调用更新数据模型。
这里,commonds指的是 slate 内部定义的一系列 Operation。和用来生产Operation的一系列Transforms 辅助方法。model 更新以后会通过一些规则来保证数据格式的规范,对model进行正确性校验,然后触发view变更。
slate 仓库下包含四个 package:
slate:这一部分是编辑器的核心,定义了数据模型(model),操作模型的方法和编辑器实例本身。slate-react:以插件的形式提供DOM渲染和用户交互能力,包括光标、快捷键等等。slate-history:以插件的形式提供undo/redo能力。slate-hyperscript:让用户能够使用JSX语法来创建slate的数据。
特点
- 灵活,完全可定制。
- 插件是一等公民,你可以以插件的形式定制自己的用于修改编辑器的行为API.
- 数据模型类似于可嵌套的
Dom树,Schema结构非常精简。 - 具有原子化操作
API,支持协同编辑。 - 使用
React作为渲染层;
slate 数据模型
slate 以树形结构来表示和存储文档内容,树的节点类型为 Node,分为三种子类型:
export type Node = Editor | Element | Text
export interface Element {
children: Node[]
[key: string]: unknown
}
export interface Text {
text: string
[key: string]: unknown
}Editor是一种特殊的Element,它既是编辑器实例类型,也是文档树的根节点Element类型含有children属性,可以作为其他Node的父节点Text类型是树的叶子结点,包含文字信息
用户可以自行拓展 Node 的属性,例如通过添加 type 字段标识Node 的类型(paragraph, ordered list, heading 等等),或者是文本的属性(italic, bold等等),来描述富文本中的文字和段落。
const initialValue = [
{
type: 'paragraph',
children: [{ text: '我是', bold: true }, { text: '一行', underline: true }, {text: '文字'}]
},
{
type: 'code',
children: [{ text: 'hello world' }]
},
{
type: 'image',
children: [],
url: 'xxx.png'
}
// 其他的继续扩展
]slate 渲染模型
slate数据模型通过slate-react视图渲染以后的组件层级如下图所示:
你会看到一些 data- 开头的自定义内置特性(attribute),比如 data-slate-node 等。
slate主要内置特性如下:
Editabledata-slate-editor用于标识编辑器组件。
Elementdata-slate-node: ‘element’|’value’|’text’;取值分别代表元素、文档全量值(适用于 Editable 上)、文本节点。data-slate-void: 若为空元素则取值为 true,否则不存在。data-slate-inline: 若为内联元素则取值为 true,否则不存在。
Leafdata-slate-leaf: 必须,取值为 true,表明对应 DOM 元素为 Leaf 节点。
Stringdata-slate-string: 若为文本节点则取值为 true,否则不存在。data-slate-zero-width: 若为零宽度文本节点则取值 ‘n’|’z’,分别指代换行、不换行,否则不存在。data-slate-length: 用于标注零宽度文本节点的实际宽度,单位为字符数。默认为 0,如果不为零则为被设置了 isVoid 的元素的文本字符的宽度。
此外,对于 Element 的 attributes 中还有以下内置特性内容:
contentEditable: 若不可编辑则取值为 false,否则不存在。dir: 若编辑方向为从右到左则取值 ‘rtl’,否则不存在。ref: 必选,当前元素的 ref 引用。Slate 会在每次 Element 渲染时将该元素和其对应 DOM 节点的映射关系添加到 ELEMENT_TO_NODE 的 WeakMap 中。若缺少 ref 则会因为 ELEMENT_TO_NODE 中映射关系的缺失而导致渲染失败和 toSlateNode 中报错。
简单实例
import React, { useState, useMemo } from 'react'
import { createEditor } from 'slate' // 创建编辑器实例的方法
import { Slate, Editable, withReact } from 'slate-react'
import { withHistory } from 'slate-history'; //以插件的形式提供 undo/redo 能力
// 初始化编辑器内容的数据。其结构类似于 vnode。
const initialValue = [
{
type: 'paragraph',
children: [ { text: '我是一行文字' } ]
}
]
export default BasicEditor = () => {
/** editor 变量为编辑器的对象实例,可以使用它提供的大量 API,也可以用来扩展其他插件。 */
const editor = useMemo(() => withHistory(withReact(createEditor())) ,[])
const [value, setValue] = useState(initialValue)
return (
<div style={{ border: '1px solid #ccc', padding: '10px' }}>
<Slate
editor={editor}
onChange={newValue => setValue(newValue)}
>
<Editable/>
</Slate>
</div>
)
}
renderElement
slate.js 提供了 renderElement 让我们来自定义渲染逻辑,不过先别着急。富文本编辑器嘛,肯定不仅仅只有文字,还有很多数据类型,这些都是需要渲染的,所以都要依赖于这个 renderElement 。
renderLeaf
renderElement 是渲染 Element ,但是它管不了更底层的 Text ,所以 slate.js 提供了 renderLeaf ,用来控制文本格式。renderElement 和 renderLeaf 并不冲突,可以一起用。
自定义事件
在 slate.js,自定义事件可以直接在
操作API
到 Editor 和 Transforms 对象里封装了很多常用的一系列 API 。可以增加样式,操作节点等。
简单插件
slate.js 提供的是编辑器的基本能力,如果不能满足使用,它提供了插件机制供用户去自行扩展。
另外,有了规范的插件机制,还可以形成自己的社区,可以直接下载使用第三方插件。
插件开发其实很简单,就是对 editor 的扩展和装饰。你想要做什么,可以充分返回自己的想象力。
数据处理
其他概念
- contenteditable
- execCommand
- Selection 和 Range
- 自定义组件
参考文献
报表导出与自动推送在大数据平台场景下的探索与实践
简述
在大数据分析平台,分析师可以通过多维交叉分析模型,生成许多能够直观反应现状的报表。这些报表可以动态更新,实时计算。我们可以通过不同的看板,把相关的报表进行聚合,聚焦。这些看板往往是对公司是非常有价值的智慧沉淀。越有价值的东西,我们就应该让它的价值最大化。我们可以把它们分享给内部同样关注和需要的人。分享一般有两种形式:
- 系统内分享:把看板分享给同样具有系统账户和权限的其他同事。
- 系统外分享:把看板信息通过其他载体分享出去。比如作为
PDF或者图片在邮件,企业微信等渠道分享。
系统外分享也是非常有用和普遍的。一方面可以作为日报/周报,周期性的反应阶段性现状。另一方面,可以让其他同事,老板非常便捷的了解到这些信息。
对于推送方式,一般有两种:
- 分析师可以把自己的看板导出为
PDF或者图片,通过邮件或者内部沟通工具进行针对性分享。 - 分析师可以创建规则(一般是推送时间,推送渠道,推送内容),将自己的看板定时的推送给相关人员。
工具
对于看板导出为 PDF,这在前端就可以实现。把 Html 页面生成PDF 的前端技术已经比较成熟,比如当下比较流行的两大利器:
html2canvas: 可以把Html转成Canvas,进而生成图片。jspdf: 可以把图片转成PDF文件。
对于看板定时推送,更多的需要借助后端的能力。比如定时任务,邮件,企业微信/钉钉/飞书等渠道的推送都需要后端来完成。报表的定时生成,需要用到无头浏览器来进行登录模拟,页面加载和图片生成(截屏)。
Node环境下可以使用Puppeteer,Java环境下可以使用ChromeDriver工具。
前端需要配合完成推送规则,渠道和内容的配置。此外,前端还需要针对导出模式对原有页面做一系列特殊处理,让导出的报表更加符合预期。比如隐藏一些无用信息,额外显示一些信息(比如在页面上 hover 上去才会显示的有用信息)。同时还要保证不会影响常规模式下页面的使用效果。
场景
工具虽好,但在实际场景中应用的时候,很多问题是工具无法帮你解决的。在大数据平台下,以下场景就比较常见:
- 懒加载
- 巨量数据请求
- 巨量数据渲染
你不能给用户导出一个数据不全,或者还没有渲染完成的报表。所以,我们必须解决懒加载的问题,并确保巨量数据已经请求并渲染完成。
懒加载
懒加载也叫按需加载,是一种被广泛应用的网页性能优化方式,它能极大的提升用户体验。比如页面很长,我们优先加载可视区域的内容,其他部分等用户滚动进入可视区域再加载。
比如在 React 技术栈项目中,我们可以使用 react-lazyload 组件实现懒加载:
import React from 'react';
import LazyLoad from 'react-lazyload';
const Demo = () => {
return (
<>
<LazyLoad height={500} offset={100}>
<>
)
}你可以简单粗暴的的把需要导出为 PDF 的页面去除懒加载。这种方法唯一的优点是尽早的开始请求和加载页面,让用户能进行尽早的导出,尽少的等待。缺点是为了实现功能而牺牲了性能。如果懒加载带来的优化微乎其微,也可以接受。
但是在很多场景,懒加载非常重要,直接去除的代价会非常大。比如大数据平台的报表看板页面。一方面,服务测的大数据计算队列是非常宝贵的资源,默认全量加载,计算队列的消耗会随着用户数几何式增长。另一方面,大数据报表的前端渲染也比较复杂耗时,如果看板的报表数量较多,一次习惯加载会导致页面卡顿。
那么,在这些懒加载必要的场景下,我们只能在用户进行导出的时候,再进行全量加载。这样页面导出 PDF 就分三步:
- 页面加载中
- 文件生成中
- 文件可下载
在使用 react-lazyload 的情况下,可以通过重新设置 offset 参数,并触发容器 scroll 事件来进行全量加载:
import React, { useState, useEffect } from 'react';
import LazyLoad from 'react-lazyload';
const Demo = (height) => {
const [offset, setOffset] = useState(100);
useEffect(() => {
const myEvent = new Event('scroll');
document.body.dispatchEvent(myEvent);
}, [offset])
return (
<>
<LazyLoad height={height} offset={100}>
<Button onClick={ () => { setOffset(height) } }>
导出为PDF
</Button>
<>
)
}这种方案的缺点就是用户在点击导出以后,要等待页面的全量加载和PDF的生成,可能需要较长时间。我们可以通过以下两种方式来进行一些优化:
- 前端侧:友好的提示用户导出的进展和进度。
- 服务测:用户在点击导出
PDF以后,服务端生成一个任务来进行PDF的导出。这样,用户可以进行其他操作,等文件生成以后通过异步回调来提示用户进行文件下载。
服务测的优化方式实现起来会比较复杂。如果服务端本身具备自动推送的功能,那么是可以复用自动推送的能力的。如果没有自动推送,前端侧优化性价比更高。
巨量数据请求&渲染
巨量数据下,数据的请求和渲染都比较耗时。那么在看板导出的场景下,我们需要进行导出时机的判断。我们在导出的时候需要确保:
- 数据请求都已返回。
DOM渲染已完成。- 图表(
Canvas)绘制已完成。
在巨量数据的情况下,
DOM渲染 和Canvas绘制 不能简单的通过在请求完成后,预留一点时间的方式来判断。
那么,有没有一种全局的,与业务逻辑解耦的方式来来进行判断,比如监听方式。
请求监听
在前端侧,我没有找到全局解耦的进行请求监听的方式,服务测非常简单。比如 Node 环境的 Puppeteer就可以很方便的进行网络监听。
对于普通的的 Http 请求, 在 Puppeteer 中监听非常便利:
await page.goto('https://www.baidu.com', {
timeout: 30 * 1000,
waitUntil: [
'load', //等待 “load” 事件触发
'domcontentloaded', //等待 “domcontentloaded” 事件触发
'networkidle0', //在 500ms 内没有任何网络连接
'networkidle2' //在 500ms 内网络连接个数不超过 2 个
]
});但是上述方式不适用于 webSocket 请求。我们可以通过以下方式来监听 webSocket 请求的所有通信:
const client = await page.target().createCDPSession();
await client.send('Network.enable');
client.on('Network.webSocketCreated', function (params) {
// console.log(`创建 WebSocket 连接:`)
});
client.on('Network.webSocketClosed',function (params) {
// console.log(`关闭 WebSocket 连接`)
});
client.on('Network.webSocketWillSendHandshakeRequest',function (params) {
// console.log(`发送 WebSocket 握手消息`)
});
client.on('Network.webSocketHandshakeResponseReceived',function (params) {
// console.log(`收到 WebSocket 握手消息`)
});
client.on('Network.webSocketFrameSent', ( frame ) => {
// console.log(`发送 WebSocket 请求`)
});
client.on('Network.webSocketFrameReceived',function (frame) {
// console.log(`收到 WebSocket 请求`)
);我们只需最后两种监听,就可以判断是否还存在未完成的 websocket 请求。
前面有提到,在前端侧我们并没有找到一种全局解耦的方式进行请求监听。但是对于页面导出为 PDF 这样的纯前端功能,需要前端来判断所有请求已完成。无法通过请求监听的方式,那只能通过记录所有请求的发送和回调这种请求判断的方式。
DOM 监听
DOM 监听的运用和实践已经比较普遍,我们使用 MutationObserver 就可以。MutationObserver 主要用于监听 DOM 元素的一系列变化。如果一段时间内页面无任何DOM 变化,我们可以认为页面渲染已经完成。
/**
* 监听 Dom 变化
*/
function domMutationObserver(resolve): void {
observer = new MutationObserver(() => {
// console.log('rendering...');
observerHeadler(resolve);
});
observer.observe(document.body, {
attributes: true,
childList: true,
subtree: true,
});
}Canvas监听
我们都知道,Canvas 是通过 JS 绘制,所以图形不会反应在 DOM 结构中,没法通过 DomMutationObserver 来进行监听。但是要进行 Canvas 绘制,必然会一直掉用 Canvas 的各种 API。我们可以通过 数据劫持 的方式来监听这些 API。如果短时间内无任何相关 API的调用,我们可以认为 Canvas 绘制已经完成。
/**
* 监听 canvas 绘制
*/
function canvasMutationObserver(resolve): void {
const canvasProto = CanvasRenderingContext2D.prototype;
const canvasProps = Object.getOwnPropertyNames(canvasProto);
canvasProps.forEach((prop) => {
const property = Object.getOwnPropertyDescriptor(canvasProto, prop);
const getter = property && property.get;
/* 监听 canvas 属性(方法就不用不监听了)*/
if (getter) {
Object.defineProperty(canvasProto, prop, {
get: function () {
// console.log('drawing...');
observerHeadler(resolve);
},
});
}
});
}
至此,我们可以通过导出时机的准确判断来导出一个懒加载的页面。
差异化导出
在报表导出的时候,用户可能希望导出的 PDF 文件中隐藏一些不必要的元素(比如操作功能区),也可能希望额外显示一些重要的信息(比如 hover 到某元素上去才显示)。这是非常普遍又合理的。
首先,我觉得在页面交互设计上,应该尽量保证页面和导出的一致性,对于个别无法保证的差异点再通过编码处理。对于处理方式,需要分 前端导出 和 自动推送 两种场景来分析。
前端导出
对于前端导出的场景,用户导出的同时,还是能够看到页面。如何做到用户无感知的差异化导出比较重要。我们可以在导出时先微调,导出后再还原。但是这种用户可感知的方案非常奇怪。新开一个不可见的窗口二次渲染又非常耗时耗能。
好在,html2canvas 提供了一个非常好用的 onclone 钩子函数作为配置参数。该函数会在 html2canvas 已经解析获取到页面 dom 副本后,在生成canvas 前调用。我们只需要给隐藏的元素增加一个 pdf_hidden 标记。在页面新增默认隐藏的需要额外显示的信息,然后增加 pdf_show 标记。然后在 onclone 钩子函数中移除或隐藏带 pdf_hidden 标记的元素;显示带 pdf_show 标记的元素即可。
html2canvas(element, {
...options,
onclone: (html) => {
const needHide = html.getElementsByClassName('pdf_hidden');
const needShow = html.getElementsByClassName('pdf_show');
if (needHide) {
Array.from(needHide).forEach((item) => {
item.remove();
});
}
if (needShow) {
Array.from(needShow).forEach((item) => {
item.setAttribute('style', 'display: block');
});
}
},
}).then((canvas) => { });onclone 钩子函数能处理很多问题。比如你页面的自定义图标( SVG )是使用 <symbol>元素来全局定义,然后在具体的 <svg/> 元素中使用 <use> 来引用的,那么你生成的 canvas 是看不到svg图标的。因为 html2canvas 是单独解析遇到的 <svg/> 元素的。这个时候,你就需要通过 onclone 钩子函数来做一些特殊处理,比如:
/**
* svg 处理
*/
function svgDealwith(element): void {
const svgs: Document[] = Array.from(element.getElementsByTagName('svg'));
svgs.forEach((svg) => {
const use = svg.getElementsByTagName('use');
if (use.length > 0) {
const fontId = use[0].getAttribute('xlink:href');
if (fontId) {
const path = document.getElementById(fontId.replace('#', '')).cloneNode(true);
svg.insertBefore(path, svg.firstChild);
setTimeout(() => {
svg.removeChild(svg.firstChild);
}, 0);
}
}
});
}自动推送
前面有提到,自动推送是后端通过无头浏览器进行页面的渲染和截屏的,是所见即所得的。如果存在导出差异,新做一个绝大部分内容一致的页面进行承载显然是不可取的。我们可以通过在原有页面增加参数来区分导出模式,然后在页面中根据是否是 导出模式,做一些差异化处理。
这无疑增加了页面的逻辑复杂度。开发得确保满足导出模式的差异化需求的同时,不影响页面的原有逻辑。我们能做的就是对差异化处理进行更好的抽象,做到尽量隔离。虽然我们没法在 导出模式 下,使用 html2canvas 的 onclone 钩子函数,但是可以复用前端导出时增加的 pdf_hidden 和 pdf_show 标记。导出模式是无头浏览器模式,不用考虑用户感知。我们只需要在页面加载以后,如果是导出模式就对带有 pdf_hidden 和 pdf_show 标记的元素进行相似处理即可。
比如在 React hooks 组件中,我们可以这样处理:
import React, { useEffect } from 'react';
// pageReady 页面渲染完成标识
const Demo = (pageReady) => {
useEffect(() => {
if (pageReady) {
const needHide = html.getElementsByClassName('pdf_hidden');
const needShow = html.getElementsByClassName('pdf_show');
if (needHide) {
Array.from(needHide).forEach((item) => {
item.remove();
});
}
if (needShow) {
Array.from(needShow).forEach((item) => {
item.setAttribute('style', 'display: block');
});
}
}
}, [pageReady])
return (
<div>
<div className="pdf_hidden">hello<div>
<div className="pdf_show" style={{display: 'none'}}>world<div>
<div>
)
}jspdf问题
最后,给大家分享一个jspdf工具在使用中遇到的一个问题:页面报表非常多的情况下,导出的pdf文件丢失部分内容。原因是我们导出的 PDF 是单页的,这样效果较好。但是 PDF 单页有高度 14400 的限制。针对这种情况,我们对 PDF 的宽高进行等比压缩来处理。
while (h1 + h2 > 14400) {
w = Math.floor(w * 0.95);
h1 = Math.floor(h1 * 0.95);
h2 = Math.floor(h2 * 0.95);
}
const h = Math.max(w, h1 + h2);
const pdf = new jsPDF({
orientation: 'p',
unit: 'pt',
format: [w, h],
});
参考资料
koa中间件原理
中间件使用
通过 app.use 使用多个中间件:
const app = new Koa();
app.use(async (ctx, next) => {
//...
await next();
//...
});
app.use(async (ctx, next) => {
//...
await next();
//...
});
// 最后一个中间件不需要 next
app.use(async ctx => {
ctx.body = "Hello World";
});
//...
中间件总体框架
中间件总体流程的核心代码如下:
class Application extends Emitter {
constructor() {
super();
this.middleware = [];
},
use(fn) {
this.middleware.push(fn);
return this;
},
callback() {
const fn = compose(this.middleware);
return function(req, res) {
return fn(ctx);
};
},
listen(...args) {
const server = http.createServer(this.callback());
return server.listen(...args);
}
}核心 compose 方法实现
function compose(middleware) {
return function(context, next) {
// last called middleware #
let index = -1;
return dispatch(0);
function dispatch(i) {
index = i;
let fn = middleware[i];
if (i === middleware.length) fn = next;
if (!fn) return Promise.resolve();
try {
return Promise.resolve(fn(context, dispatch.bind(null, i + 1)));
} catch (err) {
return Promise.reject(err);
}
}
};
}
JS之正则表达式
在
JavaScript中,正则表达式也是对象。用于匹配字符串中字符组合的模式。
如何创建
- 字面量(常用):
Var regExp = /(^\s+)|(\s+$)/g RegExp对象:Var regExp = new RegExp("(^\s+)|(\s+$)", "g")
其中 g 表示全文匹配多次,与之相关的还有 i 和 m,i 表示匹配时忽略大小写,m 表示多行匹配,如果多个条件同时使用时,则写成:gmi。
书写语法
() : 的作用是提取匹配的字符串。表达式中有几个()就会得到几个相应的匹配字符串。比如 (\s+) 表示连续空格的字符串。
[] : 是定义匹配的字符范围。比如 [a-zA-Z0-9] 表示字符文本要匹配英文字符和数字。
{} : 一般用来表示匹配的长度,比如 \d{3} 表示匹配三个空格,\d[1,3]表示匹配1~3个空格。
^ : 匹配一个字符串的开头,比如 (^a) 就是匹配以字母a开头的字符串。^ 还有另个一个作用就是取反,比如[^xyz] 表示匹配的字符串不包含xyz
$ : 匹配一个字符串的结尾, 比如 (b$) 就是匹配以字母b结尾的字符串。
\d : 匹配一个非负整数, 等价于 [0-9]
\s : 匹配一个空白字符
\w : 匹配一个英文字母或数字,等价于[0-9a-zA-Z]
*: 表示匹配前面元素0次或多次,比如 (\s*) 就是匹配0个或多个空格+: 表示匹配前面元素1次或多次,比如 (\d+) 就是匹配由至少1个整数组成的字符串?: 表示匹配前面元素0次或1次,相当于{0,1} ,比如(\w?) 就是匹配最多由1个字母或数字组成的字符串
常用方法
- test: 用来检测字符串是否匹配某一个正则表达式,如果匹配就会返回true,反之则返回false
- match: 获取正则匹配到的结果,以数组的形式返回
/\d+/.test("123") ; //true
/\d+/.test("abc") ; //false
"186a619b28".match(/\d+/g); // ["186","619","28"] replace: 字符串对象的一个方法,包含 2 个参数。- 第 1 个参数可以是一个普通的字符串或是一个正则表达式。
- 第 2 个参数可以是一个普通的字符串或是一个回调函数。
如果第1个参数是 RegExp, JS会先提取RegExp匹配出的结果,然后用第2个参数逐一替换匹配出的结果。
// 英文姓和名反转
var re = /(\w+)\s(\w+)/;
var str = "John Smith";
var newstr = str.replace(re, "$2, $1"); // Smith, John
// 千分位
var str = "1234567890";
str.replace(/\d{1,3}(?=(\d{3})+$)/g, function(match) {
return match + ',';
});千分位详简:正则表达式/\d{1,3}(?=(\d{3})+$)/g中的\d表示匹配数字,{1,3}表示匹配1到3次,\d{1,3}表示匹配连续的1到3个数字,\d{3}匹配连续的三个数字,(?=)表示反向匹配,即为从后向前匹配,(?=(\d{3})+$)就表示从后向前三位数字一匹配,至少匹配一次,而最前面必须有1到3个数字,即第一次的\d{1,3},最后的参数g表示全局匹配,匹配完所有。
参考资料
《ReactJS性能剖析》(译)
原文地址。带补充标示的地方是翻译过程中拓展的知识点。
今天,我们来看看如何使用 React 的 Profiler API 来测试 React 的渲染性能; 如何使用 React 实验性的 交互追踪 API 来追踪 React 的交互;如何使用 Timing API 来测量自定义指标。
为了方便演示,我们将使用一个展示电影列表的应用。
React Profiler API
React 提供的 Profiler API 用于测量 渲染和渲染成本,以帮助我们定位应用程序缓慢的瓶颈。
import React, { Fragment, unstable_Profiler as Profiler} from "react";
Profiler 使用 onRender 回调作为一个 prop,被分析的树中的组件每次提交更新时,这个回调都会被执行。
const Movies = ({ movies, addToQueue }) => (
<Fragment>
<Profiler id="Movies" onRender={callback}>
为了测试,让我们试着使用 Profiler 来测量部分 Movies 组件的渲染时间。像这样:
Profiler 的 onRender 回调接收一些参数,用于描述渲染的内容和渲染时间。这些参数如下:
id: 提交更新的Profiler树的 “id“ 属性。phase: “mount“ (首次加载) 或 “update“ (重现渲染)actualDuration: 提交更新的渲染时间baseDuration: 没有记忆化(memoization)的情况下,渲染所有子节点的估时startTime: React 开始渲染的时间commitTime: React 完成渲染的时间interactions: 引发更新的具体交互
补充:
Memoization是一种将函数返回值缓存起来的空间换时间的方法。原理很简单,就是把函数的每次执行结果都放入一个键值对(数组也可以)中,在接下来的执行中,在键值对中如果有值,直接返回该值,没有才去执行函数体求值并缓存。现代JavaScript中经常使用这种技术。React useMemo就是通过memoization来提高性能的。
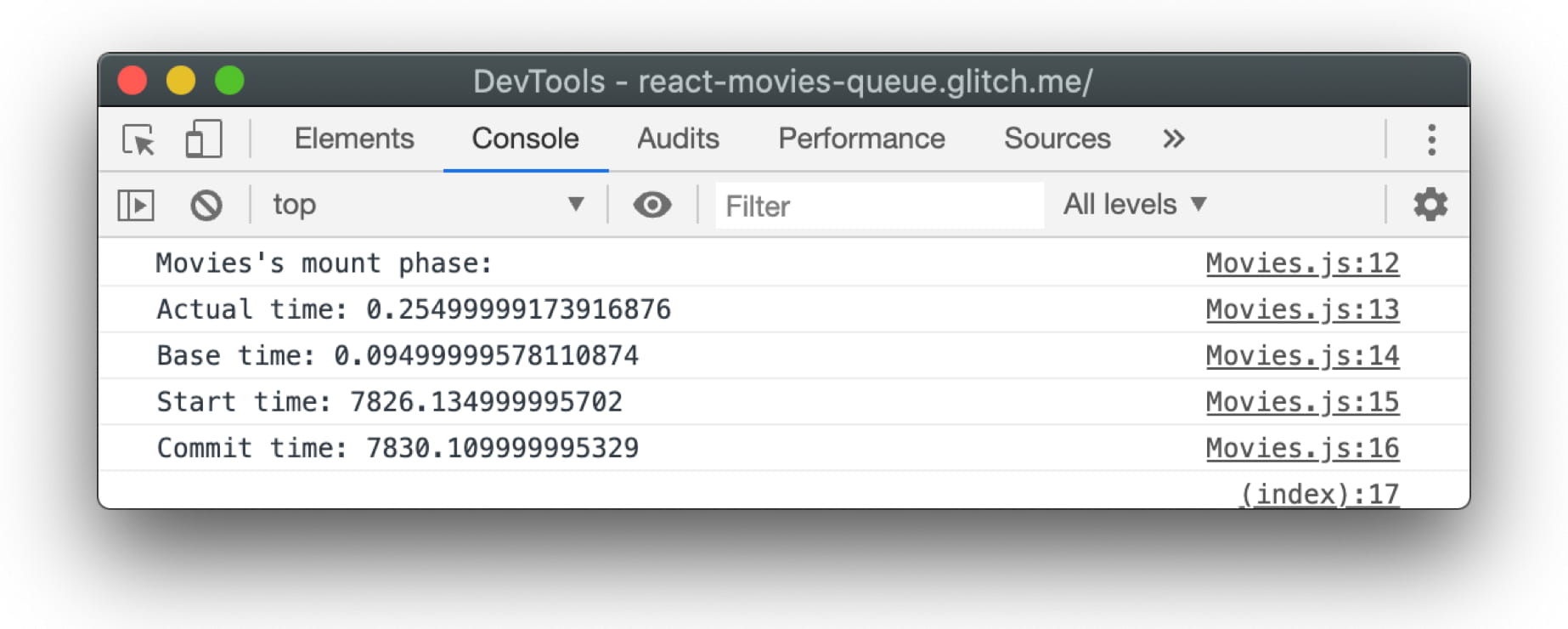
const callback = (id, phase, actualTime, baseTime, startTime, commitTime) => {
console.log(`${id}'s ${phase} phase:`);
console.log(`Actual time: ${actualTime}`);
console.log(`Base time: ${baseTime}`);
console.log(`Start time: ${startTime}`);
console.log(`Commit time: ${commitTime}`);
}
我们可以加载我们的页面,前往 Chrome DevTools 控制台,应该可以看到以下时间:
我们也可以打开 React DevTools,进入 Profiler 标签,直观地看到我们的组件的渲染时间。下面是火焰图的视图:
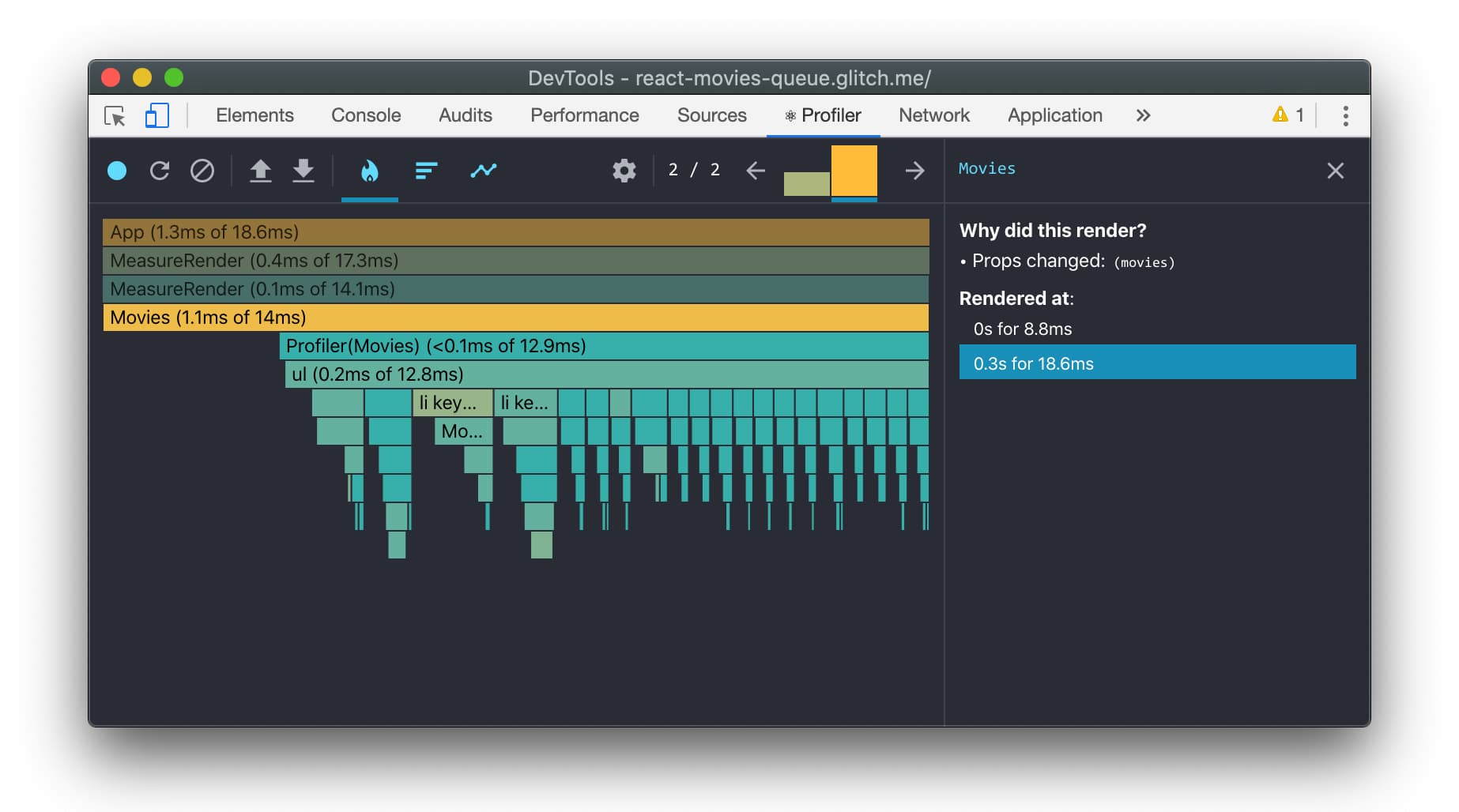
我也很喜欢使用 Ranked 视图,它是按顺序排列的,所以渲染时间最长的组件会显示在最上面。
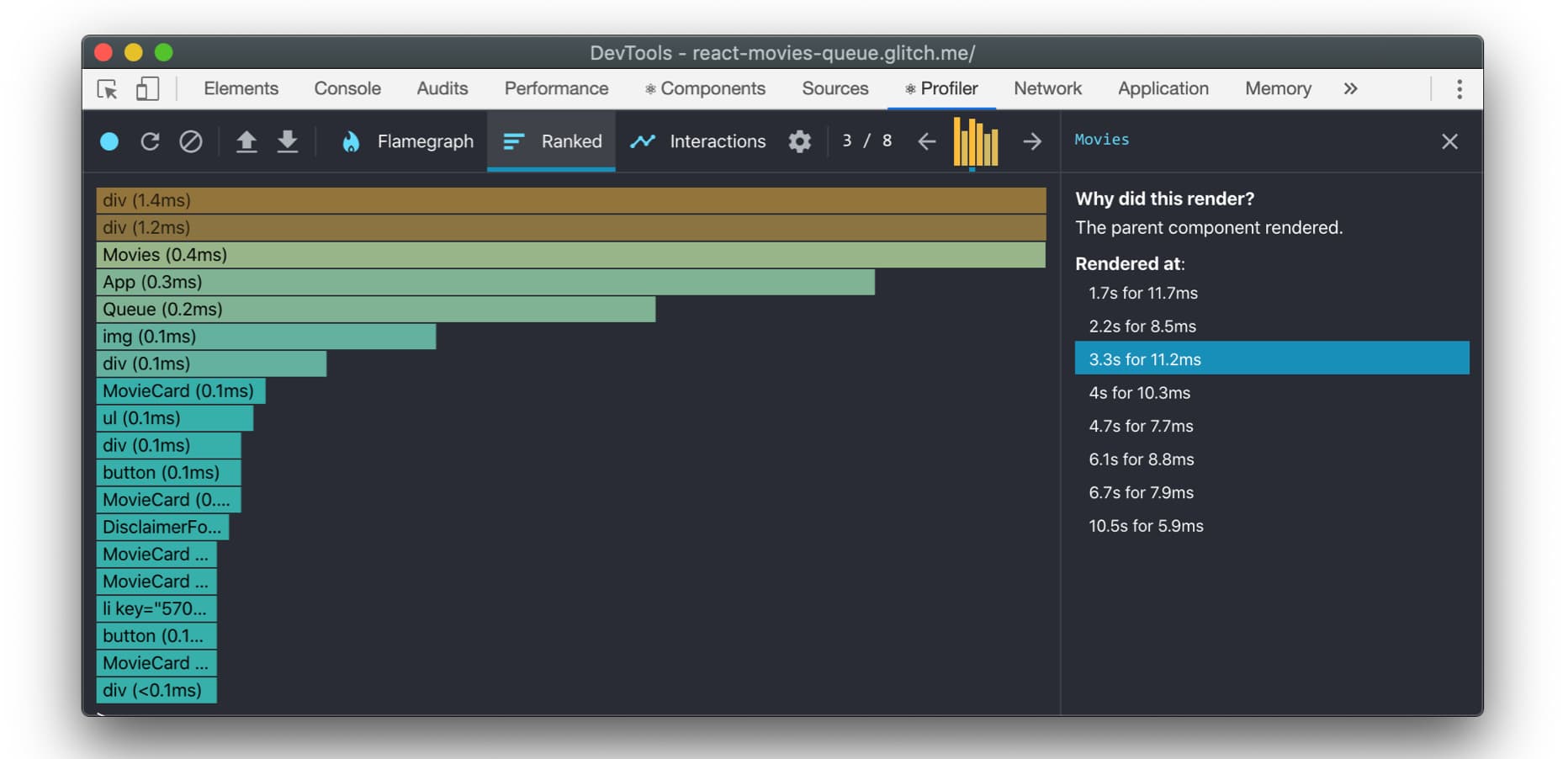
你也可以使用多个 Profilers 来测量你的应用程序的不同部分。
import React, { Fragment, unstable_Profiler as Profiler} from "react";
render(
<App>
<Profiler id="Header" onRender={callback}>
<Header {...props} />
</Profiler>
<Profiler id="Movies" onRender={callback}>
<Movies {...props} />
</Profiler>
</App>
);
补充:
React devtools的Profiler功能 只支持React v16.5+构建的应用的追踪。因为React 16.5添加了对开发者工具的Profiler插件的支持。
但是,如果你想进行交互追踪怎么办?
交互追踪 API
如果我们能够追踪交互(例如点击用户界面),以回答 “这个按钮的点击需要多长时间来更新DOM?”这样的问题,那将是非常强大的。感谢Brian Vaughn,React 通过新的 scheduler包中的交互追踪 API 对交互追踪提供了实验性支持。这里有更详细的记录。
交互被注释为一个描述(例如 “点击添加到购物车按钮”)和一个时间戳。交互也应该提供一个回调,在那里你可以做与交互有关的工作。
在我们的 “Movies“ 应用程序中,我们有一个 “将电影添加到队列 “ 按钮(”+”)。点击这个按钮将电影添加到你的观看队列中。
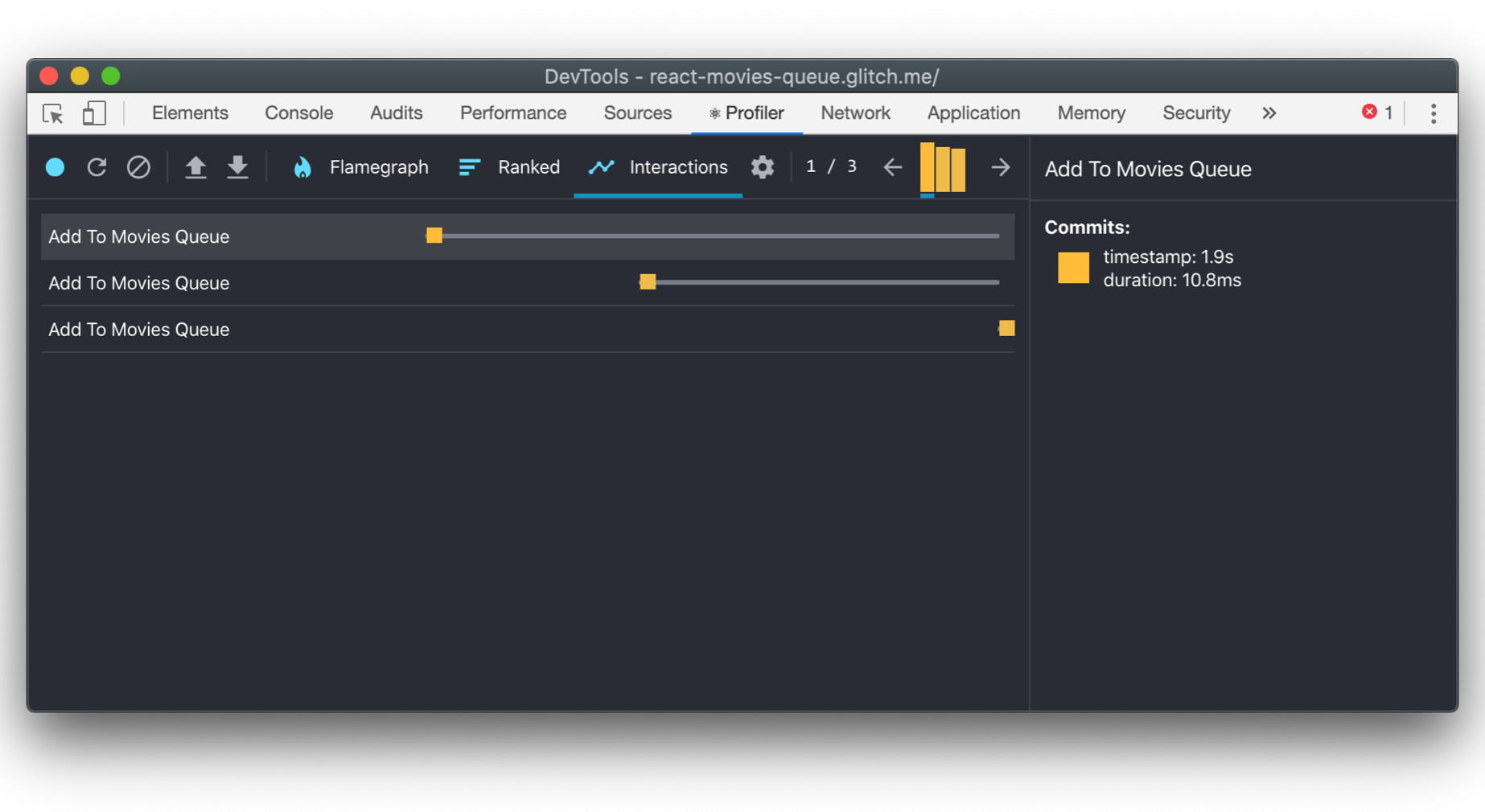
下面是一个追踪这种交互的状态更新的例子。
import { unstable_Profiler as Profiler } from "react";
import { render } from "react-dom";
import { unstable_trace as trace } from "scheduler/tracing";
class MyComponent extends Component {
addMovieButtonClick = event => {
trace("Add To Movies Queue click", performance.now(), () => {
this.setState({ itemAddedToQueue: true });
});
};
}我们可以记录这种交互,并在 React DevTools 中看到它的持续时间:
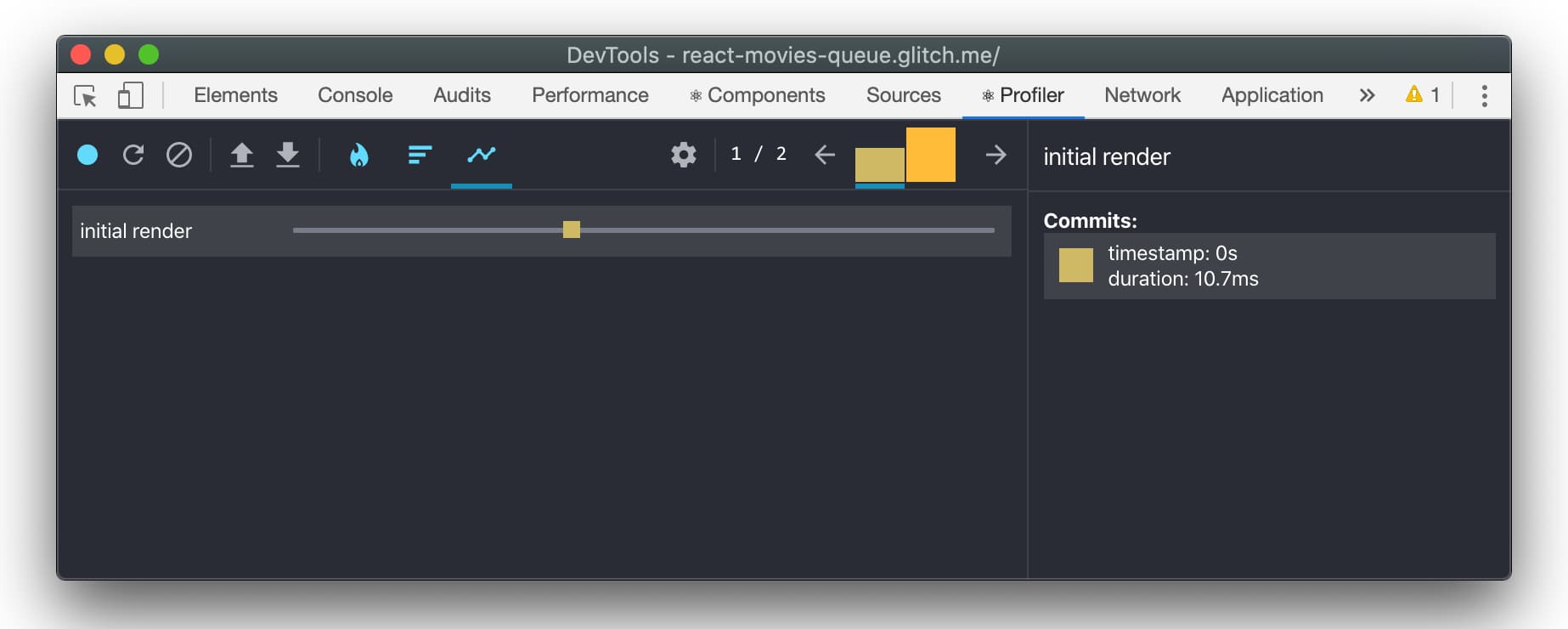
我们也可以使用交互追踪API来追踪初始渲染,如下所示:
import { unstable_trace as trace } from "scheduler/tracing";
trace("initial render", performance.now(), () => {
ReactDom.render(<App />, document.getElementById("app"));
});
Brian在他的 React gist 中涵盖了更多的交互追踪的例子,比如如何追踪异步交互。
补充:
Github提供了一个非常有用的服务Gist。开发人员可以使用Gist记录他们的代码片段,但是Gist不仅仅是为极客和码农开发的,每个人都可以用到它。
Puppeteer
对于更深入的 UI 交互脚本跟踪,您可能会对 Puppeteer 感兴趣。Puppeteer 是一个 Node 库,它提供了一系列 高级 API,用于通过 DevTools 协议控制 无头 Chrome 浏览器。
它暴露了 trace.start()/stop() 助手,用于捕获 DevTools 的性能追踪情况。下面,我们使用它来跟踪单击主按钮时发生的情况:
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
const navigationPromise = page.waitForNavigation();
await page.goto('https://react-movies-queue.glitch.me/')
await page.setViewport({ width: 1276, height: 689 });
await navigationPromise;
const addMovieToQueueBtn = 'li:nth-child(3) > .card > .card__info > div > .button';
await page.waitForSelector(addMovieToQueueBtn);
// Begin profiling...
await page.tracing.start({ path: 'profile.json' });
// Click the button
await page.click(addMovieToQueueBtn);
// Stop profliling
await page.tracing.stop();
await browser.close();
})()加载 profile.json 到 DevTools 的 Performance 面板中,我们可以看到点击按钮后的所有 JavaScript 函数调用:
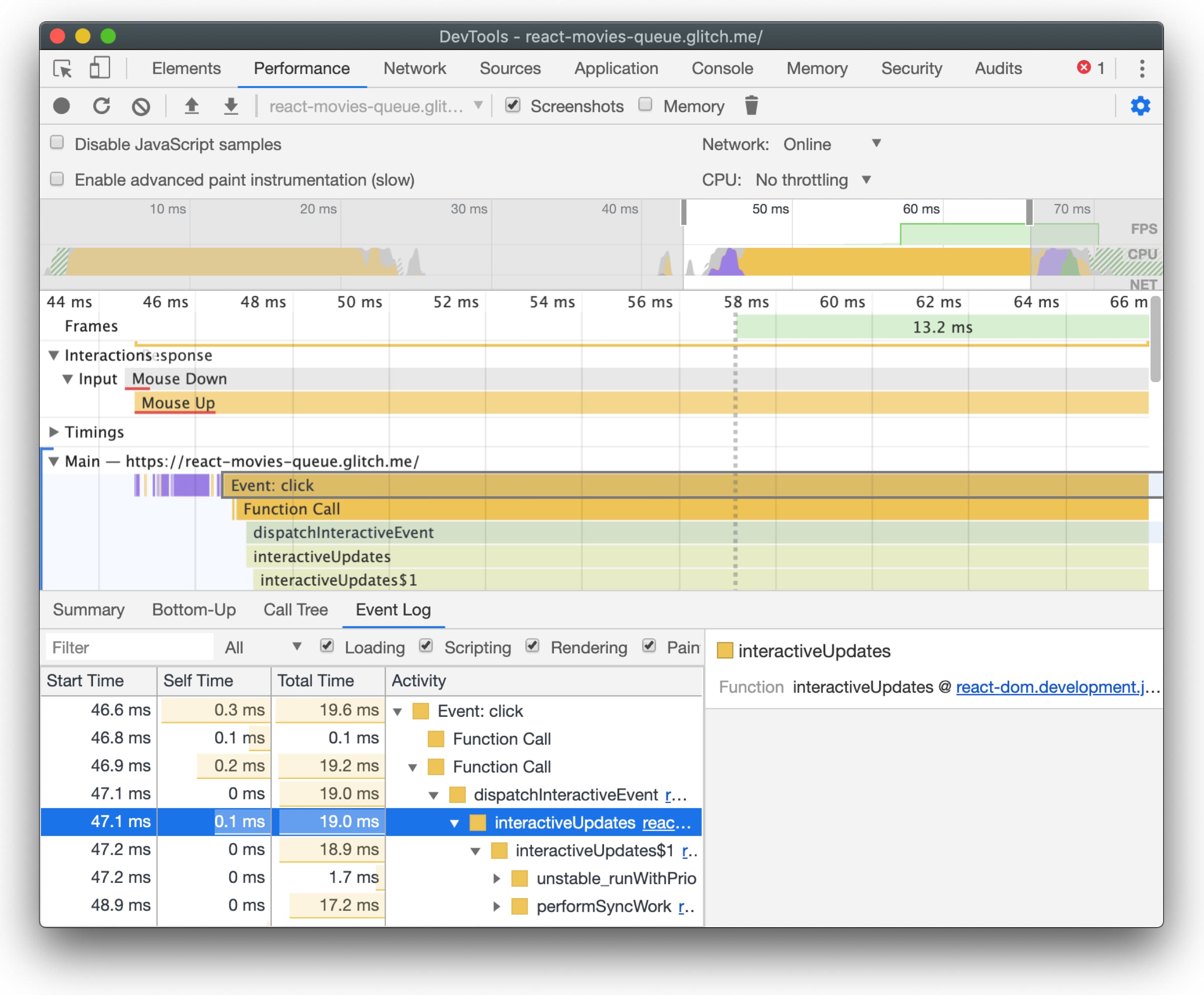
如果你有兴趣阅读更多关于这个主题的内容,请查看 Stoyan Stefanov 的文章 JavaScript组件级CPU成本。
User Timing API
User Timing API允许使用 高精度时间戳 为应用程序度量自定义性能指标。Window.performance.mark() 存储具有关联名称的时间戳,而 window.performance.measure() 存储两个标记之间经过的时间。
// Record the time before running a task
performance.mark('Movies:updateStart');
// Do some work
// Record the time after running a task
performance.mark('Movies:updateEnd');
// Measure the difference between the start and end of the task
performance.measure('moviesRender', 'Movies:updateStart', 'Movies:updateEnd');在使用 Chrome DevTools 的 Performance 面板分析 React 应用程序时,你会发现一个名为 “Timings” 的部分,里面包含了你的 React 组件的处理时间。在渲染时,React 能够通过 User Timing API 发布该信息。
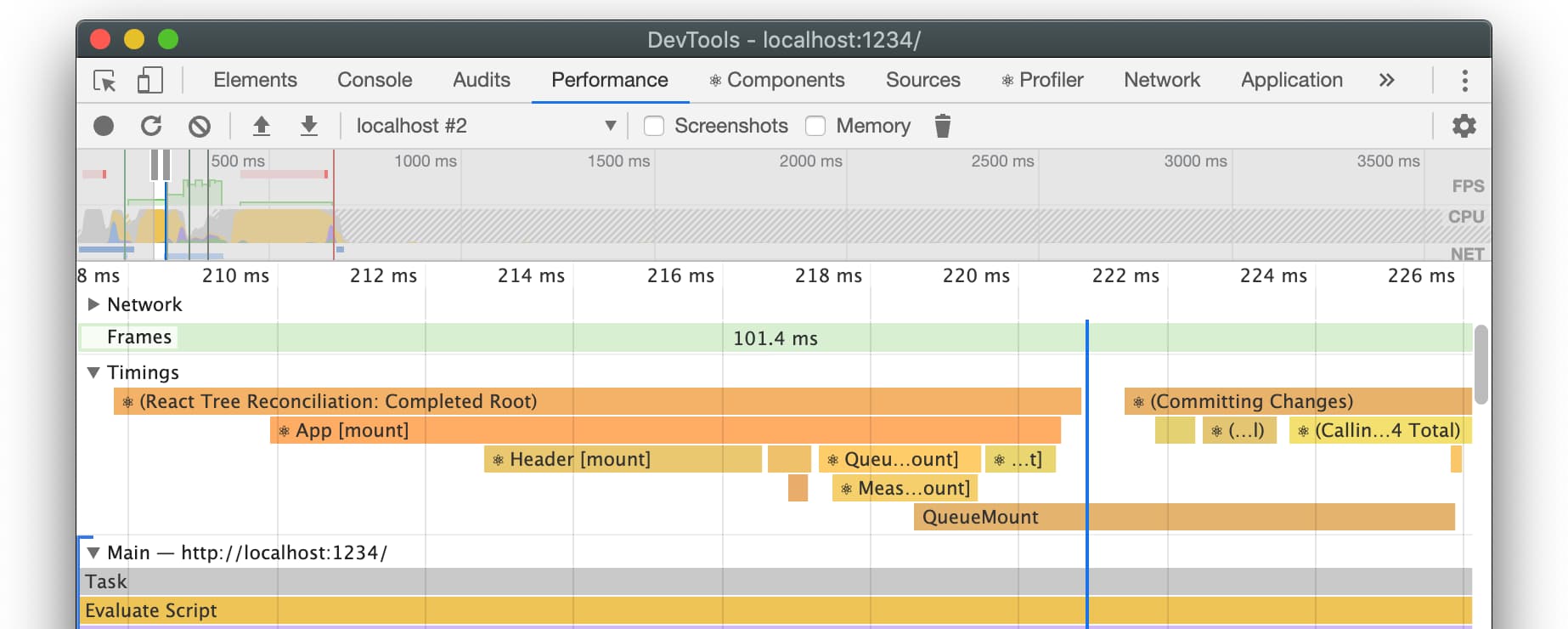
注意: React 正在从他们的 DEV 包中移除 User Timing,以支持 React Profiler,后者提供了更准确的计时。他们可能会在未来的3级浏览器中重新添加 User Timing。
纵观整个 web,你会发现 React 应用利用 User Timing 来定义自己的定制指标。其中包括 Reddit 的“Time to first post title visible” 和 Spotify 的 “Time to playback ready“:
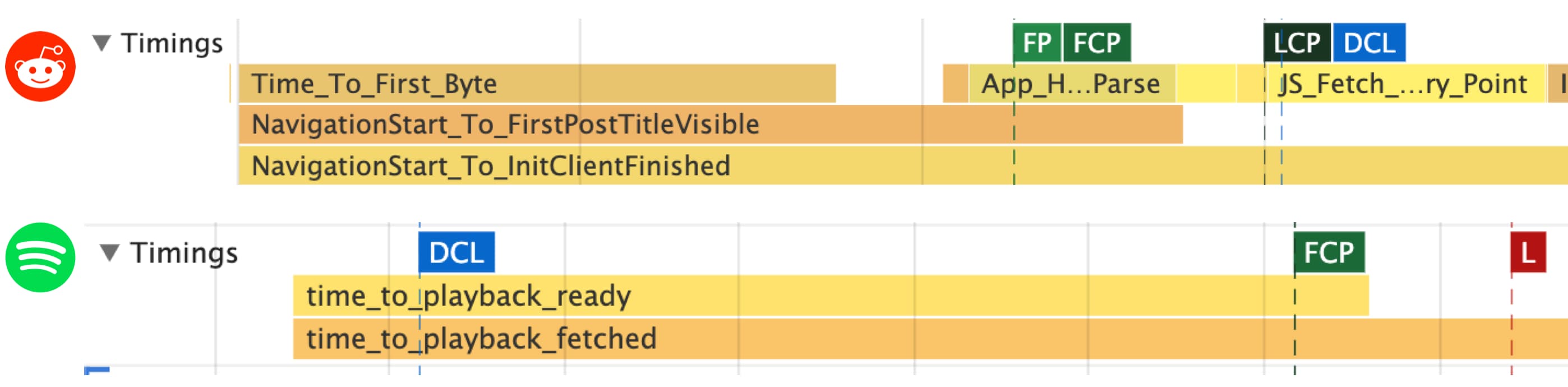
补充:
Spotify是世界上最大的音乐流媒体服务。
自定义的 User Timing 标记和度量也可以清晰的反映在 Chrome DevTools 的 Lighthouse面板:
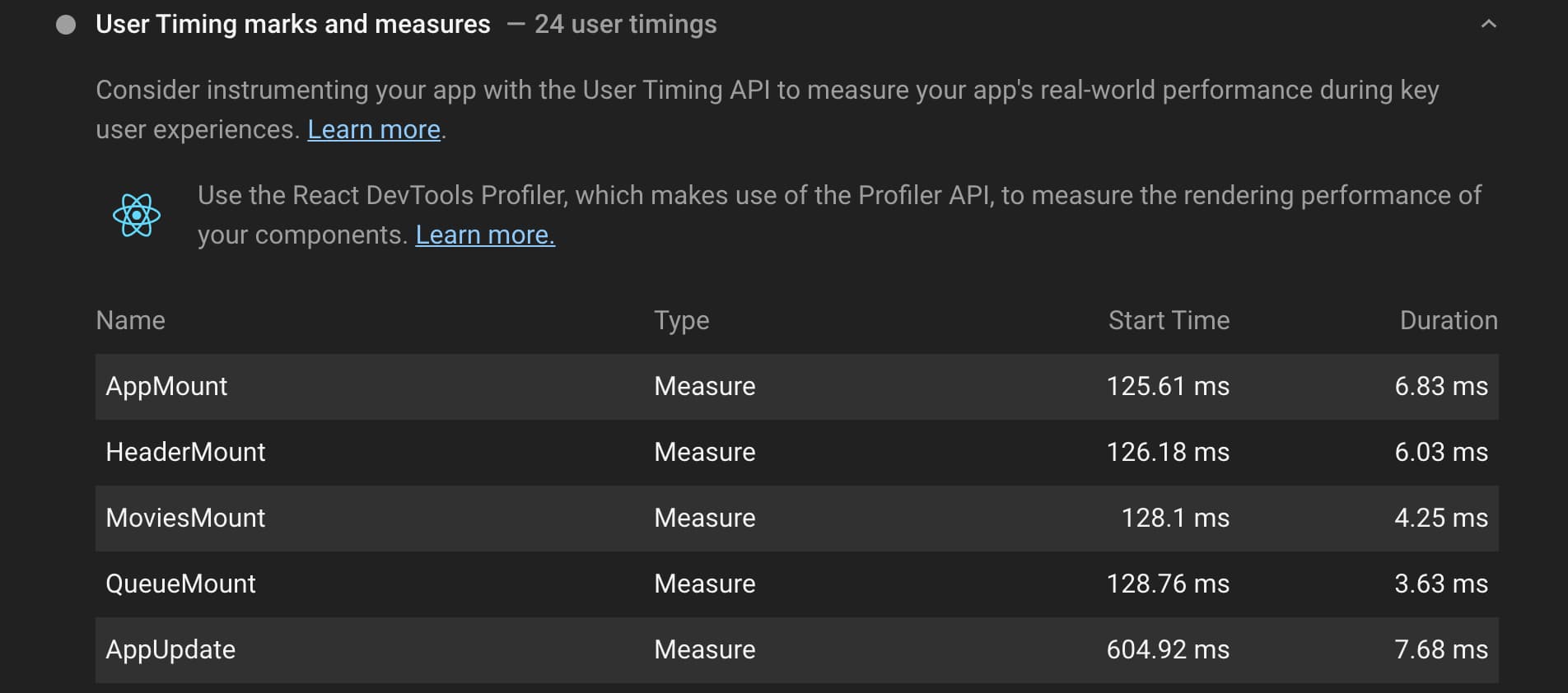
最近版本的 Next.js 还为一些事件添加了更多的 User Timing 标记和度量,包括:
- Next.js-hydration:hydration 时间。
- Next.js-nav-to-render:导航开始,直到呈现之前。
所有这些度量都将出现在 Timings 区域:
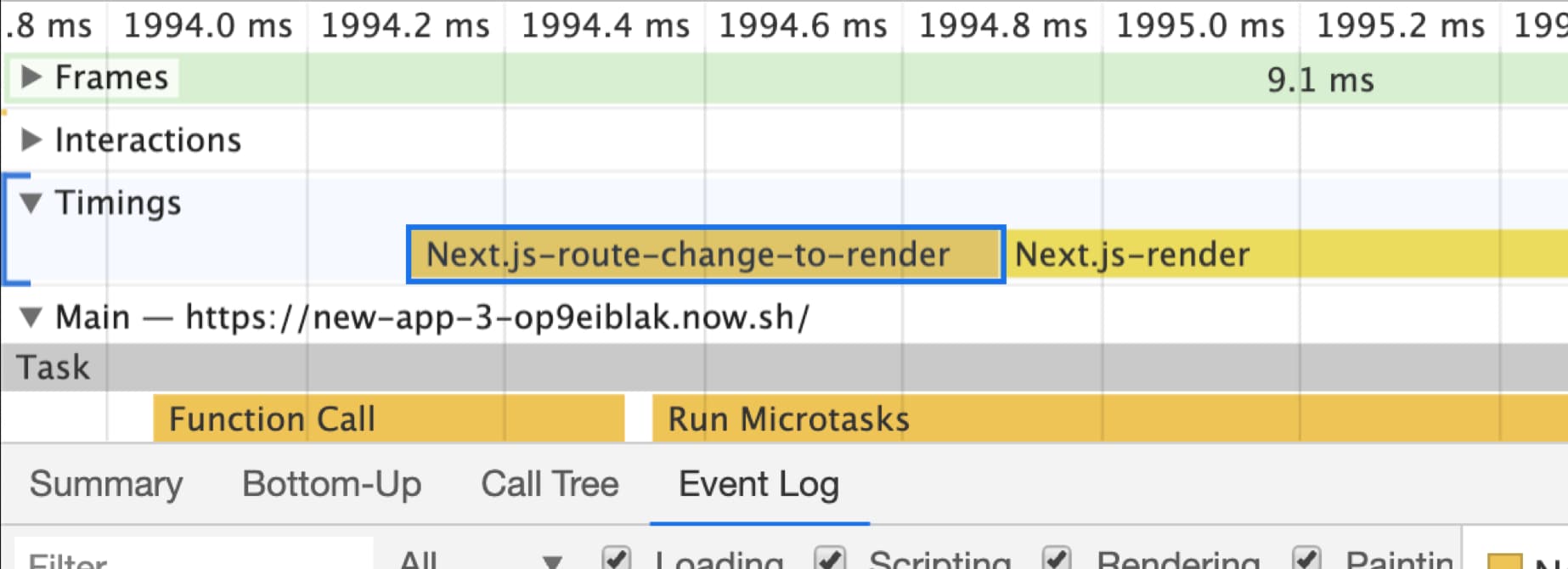
DevTools & Lighthouse
提醒一下, Lighthouse和DevTools Performance panel 面板 可用于深入分析 React 应用程序的加载和运行时性能, 突出关键以用户为中心的幸福指标:
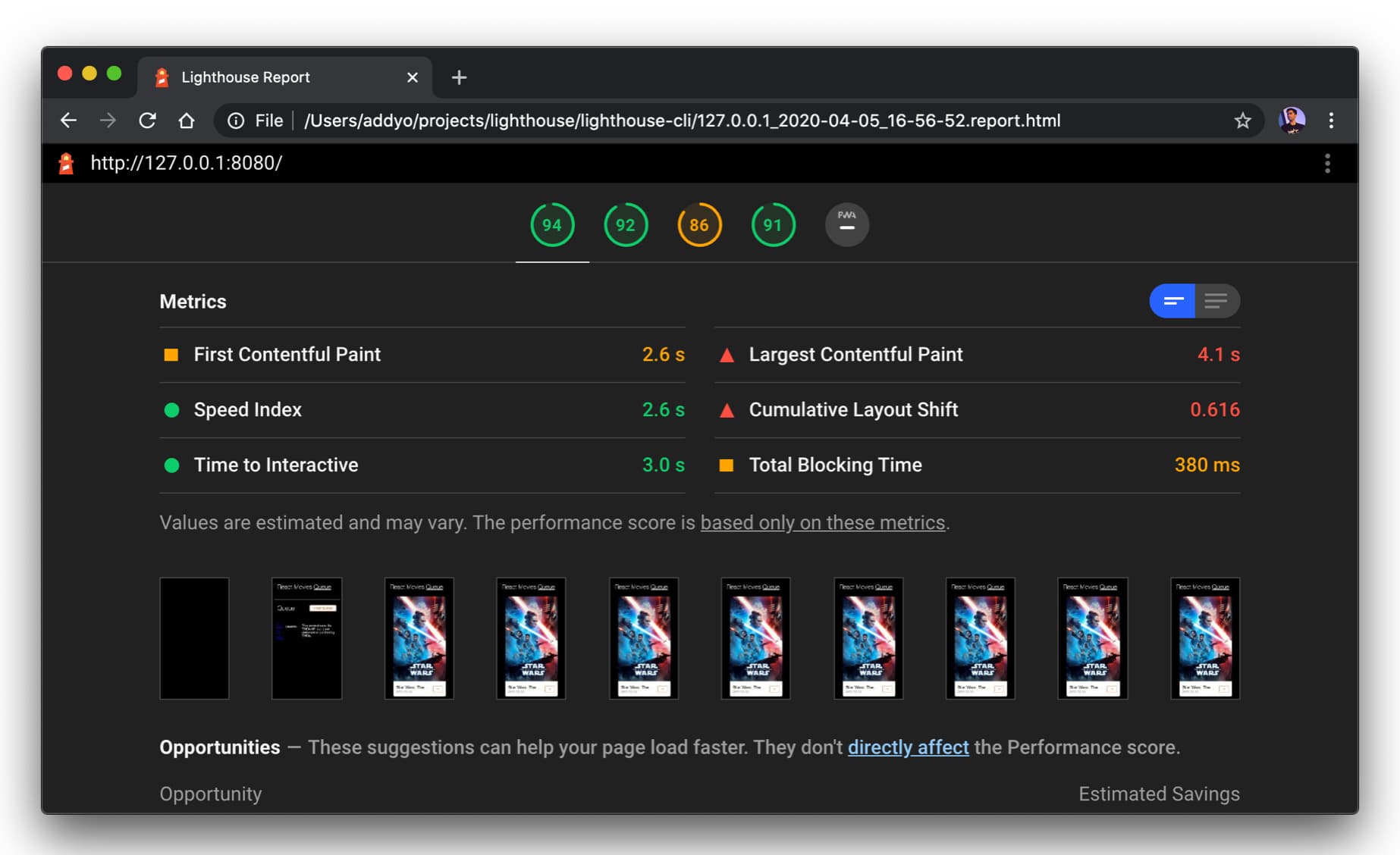
React 用户可能会喜欢像Total Blocking Time (TBT)这样的新指标,它可以衡量一个页面从最初的不可响应变得具有可靠的响应性(Time to Interactive)的过程。下面我们可以看到使用 Concurrent 模式前后,TBT的情况:

补充:
Concurrent模式是一组React的新功能,可帮助应用保持响应,并根据用户的设备性能和网速进行适当的调整。
这些工具通常有助于获得浏览器级的瓶颈视图,如延迟响应的繁重长任务(如按钮单击响应),如下所示:
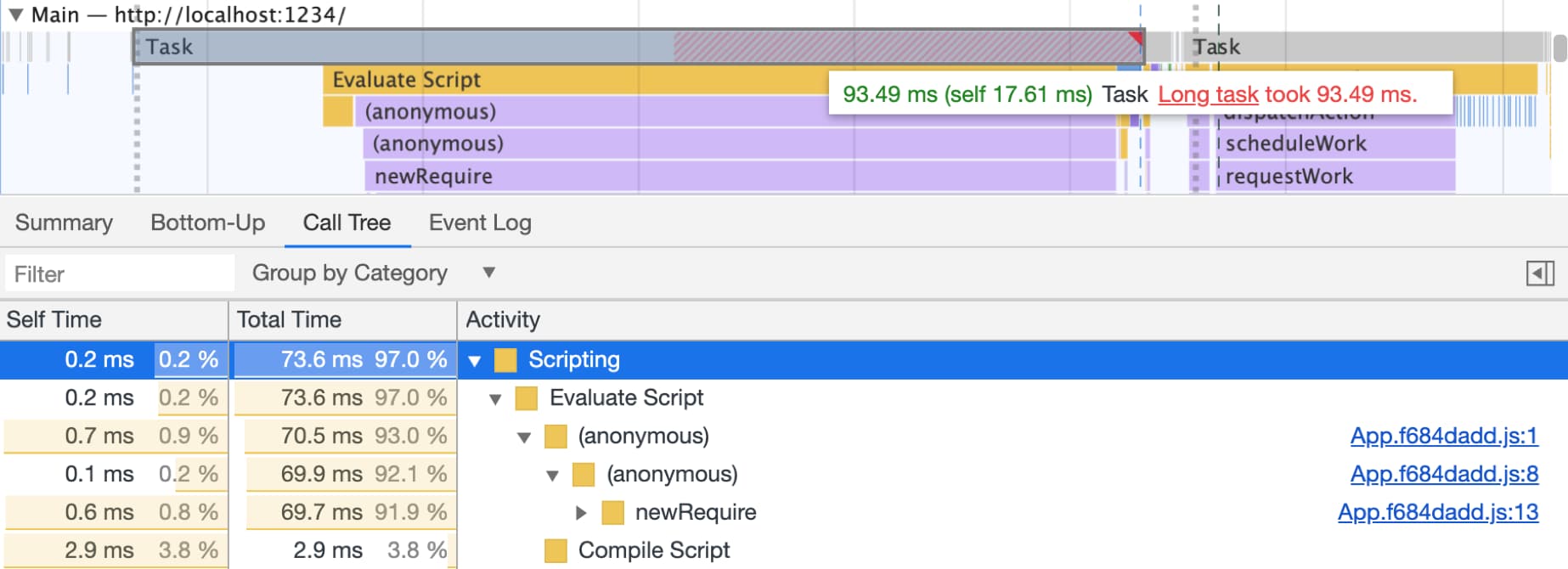
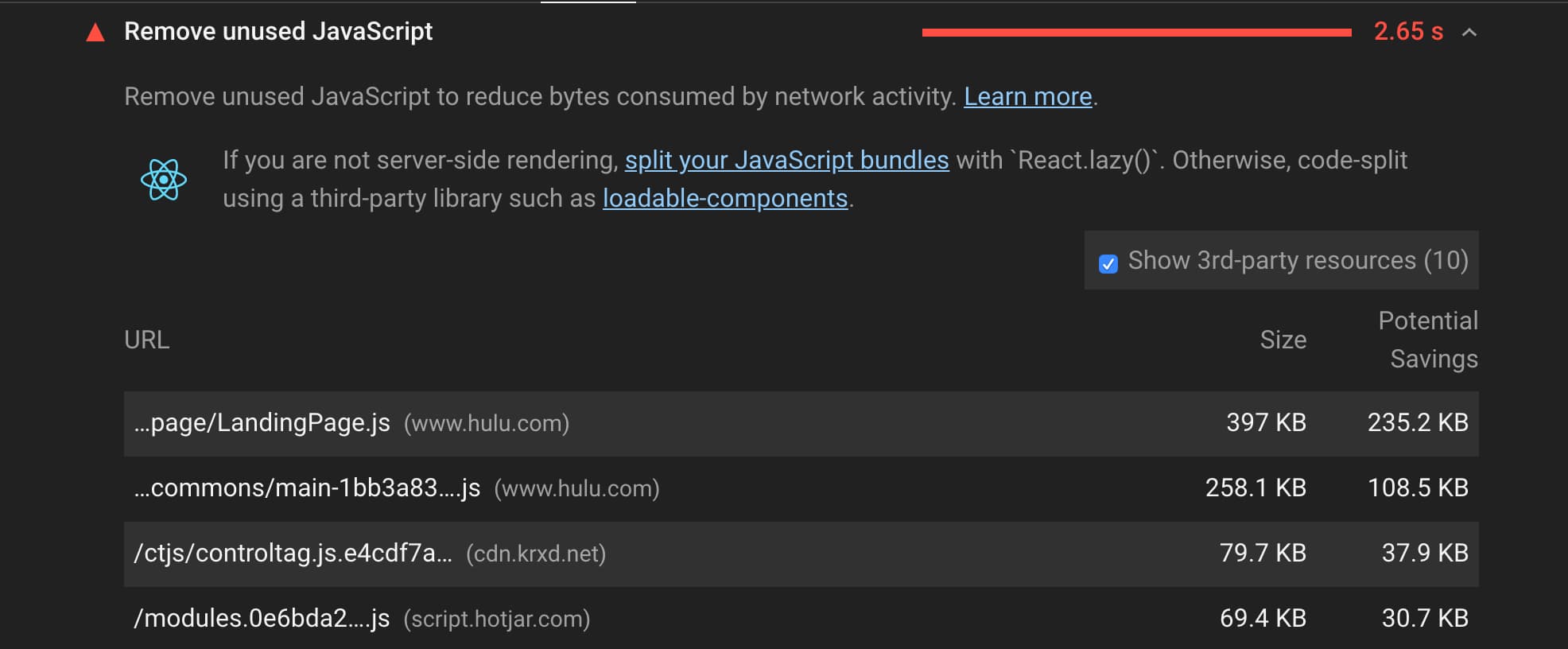
Lighthouse 还提供了一些 React 特定的的审记指引。在 Lighthouse 6.0 中,您将看到一个 remove unused JavaScript audit 的审记,高亮提示可以使用 React.lazy() 动态引入这些已加载但未使用的 JavaScript。
这总比在真实用户的硬件上对性能进行体检要好。我经常依靠webpagetest.org/easy和来自RUM和CrUX的现场数据来描绘一个更完整的画面。
Read more
Headless CMS & JAMStack
什么是CMS
CMS是 Content Management System 的缩写,意为 内容管理系统。 是一个完整的信息组织和管理的体系。它对同一类型的信息进行分类,且每一类信息都可以进行增删改查操作。此外,又采用了统一的用户和权限管理对信息的使用进行控制。内容管理系统普遍用于企业信息化建设和电子政务。
传统的 CMS 是将内容存储在数据库中,并使用一组Restful API,和对应的一组基于html的 模板文件 来管理内容呈现的管理信息系统,比如 WordPress。
WordPress是一个开源的CMS,允许用户构建 动态网站 和 博客。WordPress是网络上非常流行的博客系统,可以通过其后台管理系统,进行内容更新,自定义和管理网站。
什么是 Headless CMS
简单地说,Headless CMS(后面简称HCMS)是一种内容与表现形式分离的CMS。
HCMS 通过 API提供结构化数据(如 JSON,无样式的XML)给开发者,开发者负责通过其他技术将内容展示在网站或者客户端等独立系统中。内容创建者仍然可以使用一个编辑接口(editing interface) 修改 HCMS 内容。
传统的 CMS 前端(您在浏览器中看到的)和后端(数据库和软件层)是紧密耦合的。内容和它的呈现方式在同一套代码体系中。而 HCMS 负责内容管理,与显示内容的前端是分离的。即 HCMS 只输出 API ,不输出页面,这样可以让开发者能够用最好的技术来建立优越的用户体验。
当你的内容是可用的结构化数据,任何客户端或应用程序(无论是JAMStack应用程序还是移动设备)都可以使用它。比如,你可以使用 HCMS 为 Gatsby 站点和其他内容通道提供JSON内容源。
GatsbyJs是一个现代化的网站构建系统,拥有完整、丰富且开源的生态圈。它利用react+GraphQL产出多页面应用。通过插件,Gatsby可支持多种HCMS服务,比如Contentful、Ghost和Prismic。
如果你使用WordPress,也没有必要切换。你可以使用WordPress的REST API作为HCMS服务,这样你就可以继续使用已经熟悉的WordPress编辑工具进行内容编辑。
什么是 JAMStack
既然 HCMS 只负责内容管理,那么前端便需要一套与之契合的 架构体系 来完成显示之责,这便是 JAMStack 。
JAMStack 是指使用JavaScript、API和Markup构建的技术堆栈,JAM是JavaScript、API和Markup的简称,JAMstack一种基于客户端JavaScript,可重用API和预构建Markup的现代Web开发架构,需要符合下面三个标准:
JavaScript:请求/响应周期中的任何动态编程都由JavaScript处理,完全在客户端上运行。这可以是任何前端框架/库,甚至是轻量JavaScript。API:所有服务器端进程或数据库操作都被抽象为可重用的API,使用JavaScript通过HTTPS访问。这些可以是定制的或利用第三方服务。Markup:模板化标记应该在部署时预先构建,通常使用内容站点的站点生成器或Web应用程序的构建工具。
JAMStack 核心原则是 预渲染 和 解耦。
预渲染(
pre-rendering): 通过JAMStack,整个前端在构建过程中被预构建成高度优化的静态页面和资源。- 这意味着,你甚至可以跳过
web服务器,选择 对象存储服务(OSS) 和 内容分发网络 (CDN) 托管你的站点。 - 目前已经有很多流行的 静态站点生成器(
Static Site Generation简称SSG),比如NextJS、Gatsby、Hugo、Jekyll、Eleventy等。
- 这意味着,你甚至可以跳过
解耦(
decoupling):与服务端分离。不需要使用 数据库 或 服务器端编程语言。- 与之对应的后端服务是一系列返回
JSON或XML内容的API。这个API可以是托管的 数据存储、HCMS或 自定义应用程序。 JAMStack站点可以在构建时使用这些服务,也可以在运行时通过JavaScript直接从浏览器使用这些服务。Sourcebit通过从任何第三方资源中提取数据来帮助开发人员构建数据驱动的JAMstack站点。
- 与之对应的后端服务是一系列返回
很明显,JAMStack 和 HCMS 是高度契合的。
对象存储服务(
Object Storage Service,OSS)是一种海量、安全、低成本、高可靠的云存储服务,适合存放任意类型的文件。
JAMStack 优势
速度: 没有数据库层 和 软件服务层导致的开销。因此,它们的渲染和加载速度比传统的一体化架构的站点更快。
托管灵活性: 由于是 静态文件,
JAMStack站点可以托管在任何地方。您可以使用传统的web服务器软件,如Apache或Nginx。为了获得最佳的性能和安全性,您可以使用OSS和CDN,如Netlify、Render或AWS的S3和Cloudfront。更好的开发体验: 前端开发人员无需了解 服务器端语言 就可以构建站点。后端开发人员可以专注于
Api构建。解耦的开发团队可以并行工作,允许每个团队专注于他们最擅长的工作。使用第三方CMS服务还意味着你的开发-运营团队不必管理单独的内容栈。更好的安全性: 没有数据库和软件层意味着
JAMStack站点不容易受到SQL注入或 服务器端代码注入攻击。页面是预构建(pre-build)的,因此不会面临服务器端包含注入攻击的风险。在CDN上托管站点可以免受服务攻击。
JAMStack 最佳实践
整个项目放
CDN上- 因为
JAMStack项目不依赖服务器端代码,所以它们可以分布式而不是生活在单一服务器上。直接放CDN上提供服务,可以释放出无可匹敌的速度和性能。带来更好的用户体验。
- 因为
使用现代构建工具
- 利用现代构建工具的生态圈。这是一个快速发展的空间,你会希望今天能够使用明天的
Web标准,而不是等待明天的浏览器。比如目前用到的Babel、PostCSS、Webpack。
- 利用现代构建工具的生态圈。这是一个快速发展的空间,你会希望今天能够使用明天的
自动构建
- 因为
JAMStack的markup是预构建的,所以在你运行另一个构建之前,内容更改不会上线。将这个过程自动化会减少挫败感。你可以使用webhooks自己来完成,或者使用包含 自动服务 的发布平台。
- 因为
原子部署
- 当
JAMStack项目发展到足够大大,新的改变可能需要重新部署数百个文件。一次性上传这些文件这一进程完成前,会造成信息不一致的状态。你可以使用一个允许你进行 “原子部署(Atomic Deploys) “ 的系统来避免这种情况,在这个系统中,在所有更改的文件被上传之前,任何更改都不会上线。
- 当
即时缓存失效
- 当从构建到部署的周期成为一种常态时,你需要明白,当部署上线时,就真的在线上了。需要确保你的
CDN做好 即时缓存失效 处理。
- 当从构建到部署的周期成为一种常态时,你需要明白,当部署上线时,就真的在线上了。需要确保你的
一切尽在
Git中- 有了
JAMStack项目,任何人都应该能够进行git克隆,用标准的程序(比如npm install)安装所需的依赖项,然后就可以在本地运行整个项目。无需克隆数据库,无需复杂的安装。这减少了贡献者的摩擦,也简化了测试工作流程。
- 有了
总结
Jamstack 本质是一种增强的静态网站,它的出现很大程度上得益于各大云厂商提供的云上能力,包括更容易管控的 CDN/DNS、Serverless Function、DevOps 工具等等。
Jamstack 适合一些内容更新不太频繁的网站(比如新闻、电商、文档)。它不适合论坛,聊天室,金融信息……等高度动态化的网站。目前最大用用武之地还是在 HCMS, Headless Commerce(无头电商)这类领域。
参考&拓展资料
gatsbyJs文档
gatsbyJs官网
gatsbyJs plugins Library
JAMStack
GraphQL官网
Gatsby精粹,面向未来的blog
Next.js: Server-side Rendering vs. Static Generation
Bringing Next.js to the JAMstackhttps://cloud.tencent.com/developer/article/1439913)
Jamstack,下一代Web建站技术栈?
JS之防抖节流
什么是防抖
防抖 (debounce),顾名思义就是防止抖动。一些高频触发的事件( 如:resize、scroll、mousemove…… )会导致事件处理函数高频执行。如果事件处理函数还操作DOM,那就意味着会引发高频的渲染重绘或回流。极端情况下,就会看到明显的页面/元素抖动。
所以,防抖就是防止高频的 DOM 操作导致页面频繁的渲染。
现代浏览器内核针对这种情况,内部进行了优化:会设置一个时间阀值,把这个时间内的 DOM 改变合并渲染。即便如此,我们在实际的项目中也要做好防抖,尽量为内核减负。
什么是节流
节流 (throttle),顾名思义就是节约流量(流量是网络世界宝贵的资源,web 又是流量的主要入口之一)。广义上也可以衍生为节约资源,这里的资源主要包括我们宝贵的浏览器内核资源。
所以,节流就是要避免不必要的网络请求,避免不必要的 js执行和页面渲染。
明显,广义上的节流是包含防抖的,只是,防抖和节流在具体实现上是有差异的。
防抖和节流的区别
防抖和节流都需要设置一个时长。
防抖:延时执行,并且
时长内没有重复触发才会执行,否则重新计时。所以,最后(最新)一次事件必定响应。典型场景有:- 页面缩放(
resize): 页面缩放的时候,动态调整某些元素的大小。典型的防抖场景。 - 搜索框联想(
change): 连续输入,触发多次搜索。一方面浪费资源,另一方面,如果先联想的结果后返回,那么显示就不是最新匹配的。 - 文本编辑器(
change): 实时保存的文本编辑器。问题同上。
- 页面缩放(
节流:高频事件在
时长内处理一次即可,一般是这段时间的第一次。典型场景有:- 元素拖拽/缩放(
mousedown/mousemove): 需要实时显示元素的位置/大小,但是频率也无需和事件触发频率一致。 - 提交按钮(
click): 会发起网络请求的点击按钮。遇到暴力点击,不光有重复提交的问题,还会导致流量和浏览器内部资源大大浪费。
- 元素拖拽/缩放(
根据实际场景的需求来选择 防抖 还是 节流 。比如 元素拖拽/缩放,如果需求不要求过程只追求结果,就应该选择 防抖。
明显,我们可以通过时间戳,定时器来控制。下面,我们来看看防抖节流如何具体实现。
防抖函数
防抖的关键在于延迟执行,所以推荐使用定时器。
- 基础版: 延迟
ms毫秒执行,在这期间的其他重复请求不执行。
function debounce(func, ms) {
let timeout;
return function () {
const context = this;
const args = arguments;
clearTimeout(timeout)
timeout = setTimeout(function(){
func.apply(context, args)
}, ms);
}
}
window.onmousemove = debouce(()=> console.log(1), 1000);- 进阶版:+ 首次请求立即执行。
function debounce(func, ms, immediate) {
let timeout;
return function () {
const context = this;
const args = arguments;
if (timeout) clearTimeout(timeout);
if (immediate) {
const callNow = !timeout;
timeout = setTimeout(function () {
timeout = null;
}, ms)
if (callNow) func.apply(context, args)
} else {
timeout = setTimeout(function () {
func.apply(context, args)
}, ms);
}
}
}节流函数
节流的关键在于控制一段时间内只执行一次,所以时间戳和定时器都可以。区别是时间戳版触发是在时间段内开始的时候,而定时器版触发是在时间段内结束的时候。
- 定时器版:每
ms毫秒只执行一次。
function throttle(func, wait) {
let timeout;
return function () {
const context = this;
const args = arguments;
if (!timeout) {
timeout = setTimeout(function () {
timeout = null;
func.apply(context, args)
}, wait)
}
}
}
- 时间戳版:每
ms毫秒只执行一次。
function throttle(func, wait) {
var previous = 0;
return function () {
var now = Date.now();
var context = this;
var args = arguments;
if (now - previous > wait) {
func.apply(context, args);
previous = now;
}
}
}
参考文档
浏览器渲染原理
进程
我们知道,
应用程序能够运行,是需要占用计算机资源的。为了稳定的
并行多个应用程序,计算机必须得做好资源的合理分配和管理,这是操作系统的基本职责。进程便是操作系统进行资源分配的基本单位,是 应用程序 的载体。一个应用程序,又可以是
多进程设计, 比如现代浏览器。
现代浏览器是多进程的
在应用程序中,为了满足功能的需要,主进程会创新新的辅助进程来处理其他任务。这些辅助进程拥有全新的独立的内存空间。如果一个应用程序的这些进程需要通信,可以通过IPC (Inter process Communication )机制来进行。
我们都知道,现代浏览器 都支持多 tab ,一个 tab 对应一个 网页,其实也对应一个网页进程。进程之间互相独立的这种互不影响性 就保证了一个网页的奔溃,不会影响其他网页。当然,如果主进程奔溃,就会影响所有网页了。
不同的浏览器使用不同的架构,下面主要以Chrome为例,主要有 4 个进程:
浏览器主进程(Browser Process): 负责协调、主控,有且只有一个。
- 负责 浏览器界面与用户交互。如前进,后退等;
- 负责各个
tab页面的管理,创建和销毁; - 网络资源下载,文件访问等。
渲染进程(Render Process):也称 渲染引擎,也是我们常说的 浏览器内核。
- 负责 页面渲染,脚本执行,事件处理等
- 它是
多线程的。
插件进程(Plugin Process):负责控制网页使用到的插件。
- 每种插件对应一个进程,仅当使用该插件时才创建。
GPU进程(GPU process):负责所有显示任务。
- 最多一个,用于
3D绘制和硬件加速。
多进程架构的好处
更高的容错性
- 现代
Web(HtmlJsCss) 的复杂性已经越来越高,代码出现Bug可能直接导致 渲染引擎 奔溃。 - 多个
tab页面会开多个 渲染进程,一个页面的崩溃不会影响其他页面的正常运行。
更高的安全性和沙盒性(sanboxing)
- 网络上一直以来,都充斥着各种恶意代码攻击,甚至会利用一些漏洞安装恶意软件和插件。
- 浏览器多进程的设计,通过对不同进程设置不同的权限,创造 沙盒式 运行环境,使其更安全可靠。
更高的相应速度
- 进程是操作系统进行资源分配的基本单位。
- 单进程设计就意味着,进程中的各个任务会相互竞争,抢夺
CPU资源。而多进程架构正好改善了这一点,提升了响应速度。
多进程虽然有诸多好处,但是缺点也很明显,那就是 费内存。
为了节约内存,Chorme浏览器设计和提供了四种 进程模式(Process Models)
Process-per-site-instance: 默认;同一个site-instance使用一个进程。Process-per-site: 同一个site使用一个进程。Process-per-tab: 每个tab使用一个进程。Single process: 所有tab公用一个进程。
那么,site 和 site-instance 的区别是什么呢?
site: 协议和主域名一致则为 同site(和 同源策略 不同,不需要 子域名 和 端口号 一致)。site-instance: connected pages from the same site。包括 同site页面,还包括由这些页面打开的新页面。即通过<a target='_blank'></a>和window.open打开的页面。
Chorme浏览器默认选择Process-per-site-instance模式,兼容了性能和易用性,是一种中庸的选择之道。
线程
前面提到,渲染进程又是 多线程 设计,那 线程 又是什么由来呢?
应用程序越来越多,功能迭代使得应用程序对 资源的消耗 也越来越大。
为了提升进程的效率,避免计算机资源的浪费,一个进程又可以有多个
线程。线程是CPU进行任务调度的基本单位。可以理解为进程的一个控制单元。一个进程至少有一个线程。所有线程可共享进程所拥有的全部资源。
浏览器内核是多线程的
浏览器内核 主要有以下几个 线程:
GUI线程
DOM解析,CSS解析,生成渲染树。- 当
RenderObject树需要更新样式属性时,即发生重绘(Repaint)。 - 当
RenderObject树中元素尺寸,布局,显示隐藏等发生变化,即发生回流(reflow)。 - 在发生
重绘和回流时,会形成GUI更新队列。 GUI线程和JS引擎线程互斥。当JS引擎执行时,GUI线程会被挂起。GUI更新队列只能等到JS引擎空闲时被执行。
JS引擎线程(比如 V8)
- 也称
JS内核,负责解析Javascript脚本,运行代码。 GUI渲染线程与JS引擎线程是互斥的。所以如果JS执行的时间过长,这样就会造成页面的渲染不连贯,导致页面渲染加载阻塞。
事件触发线程
- 用来控制事件循环(
Event Loop)。 - 配合
JS引擎处理异步代码。JS异步代码的回调函数会形成一个任务队列,等待JS引擎空闲时被调用。
定时触发器线程
setInterval与setTimeout所在线程(因为JS引擎是单线程的, 如果处于阻塞线程状态就会影响记计时的准确)。定时器事件会在计时完毕后,添加到事件队列中,等待JS引擎空闲后执行。
异步http请求线程
- 在
XMLHttpRequest在连接后是通过浏览器新开一个异步http请求线程来请求。 - 将检测到状态变更时,如果设置有回调函数,异步线程就产生
状态变更事件,将这个回调再放入事件队列中。等待JS引擎空闲后执行。
浏览器渲染流程
主要任务
浏览器渲染流程的主要任务如下(不一定按顺序):
html文档解析
- 遇到
JS脚本,会加载并执行。 - 遇到
CSS代码,同步进行解析。 - 过程中可能会被
CSS和JS的加载而执行阻塞 - 解析完成,生成
Dom树。 - 在控制台
console里面输入document可查看Dom树.
CSS解析
html解析过程中,会对遇到的CSS同步进行解析:CSS包括: 标签自带样式;通过link/@import引用的样式文件;style标签内的样式;元素内嵌的样式。- 转换样式表中的属性值,使其标准化,比如
em转px,bold转换成一个具体的数值,red转换城rgb(255,0,0)等。 - 计算每个
DOM的具体样式。 CSS继承。
不会阻塞
html解析流程。解析完成,生成
CSSOM(CSS Object Model)。在控制台
console里面输入document.styleSheets可查看CSSOM。
JS脚本执行
html解析过程中,会对遇到的JS脚本进行加载并执行。CSS解析与JS脚本的执行互斥(JS可能会等待CSSOM生成以后执行)。Webkit内核中进行了JS执行优化,只有在JS访问CSS时才会发生互斥。
Dom树 和 CSSOM 结合生成 渲染树(Rendering Tree)
- 和
Dom树节点不是完全对应的。 - 比如
head标签下的所有内容,display:one的元素就不会被添加到渲染树中。 visibility: hidden的元素在渲染树中。- 渲染树是一系列将被渲染的对象。
布局(layout):
计算渲染树各节点元素的尺寸、位置等。
这里的计算实际上是“三维”的计算,分层布局(这里涉及
复合图层和硬件加速的概念)。布局阶段的输出就是我们常说的盒子模型,它会精确地捕获每个元素在屏幕内的确切位置与大小。
打开
Chrome控制台,输入command+shift+p,选择show Rendering, 选择Layer borders中看到,黄色的就是复合图层。
绘制(paint):绘制页面像素信息。
- 浏览器会遍历渲染树,调用渲染器的
paint()方法在屏幕上显示其内容。 - 渲染树的绘制工作是浏览器通过将各层的信息发送给
GPU,GPU会进行合成(composite),显示在屏幕上。 - 打开
chrome控制台,输入command+shift+p,选择show Layers,可以查看图层。
回流 和 重绘
回流(Reflow): 基于渲染树的页面布局,是一种流式布局。当页面元素修改,引起布局的变化,浏览器就会从html 这个 root 根结点 自上而下遍历,进行重新计算渲染。引发布局变化的操作主要有:
- 页面第一次渲染(初始化)
DOM树变化(如:增删节点)Render树变化(如:显示隐藏,位置,大小等修改)- 浏览器窗口
resize
重绘(Repaint): 页面元素改变的时候,浏览器会对涉及内容进行重画。
- 回流必定引起重绘。
- 仅元素样式改变,不影响布局的情况下,重绘可单独触发。
相关事件
domContentLoaded:当html解析完成,生成Dom树后触发。
- 此时
Dom元素可以被访问。 - 此时
document.readystate从loading变成interactive
onload事件触发: 页面资源全部已加载完成后触发。
- 此时 页面上所有的
DOM,样式表,脚本,图片都已经加载完成。 - 此时
document.readystate从interactive变成completed
异步脚本 和 延迟脚本
异步脚本: 带async的脚本
HTML还没有被解析完的时候,async脚本已经加载完了,那么HTML停止解析,去执行脚本,脚本执行完毕后触发DOMContentLoaded事件。HTML解析完了之后,async脚本才加载完,然后再执行脚本,那么在HTML解析完毕、async脚本还没加载完的时候就触发DOMContentLoaded事件。- 一定会在
load事件之前执行。
延迟脚本: 带 defer的脚本
- 不会影响
HTML文档的解析,而是等到HTML解析完成后才会执行。 - 肯定在
defer脚本执行结束后,DOMContentLoaded才会被触发。
渲染阻塞
JS阻塞页面: JS可能操作和修改DOM,也可能操作CSSOM来修改节点样式,所以浏览器在遇到<script>标签时,DOM构建将暂停,直至脚本完成执行(外部脚本还要先下载完成再执行),然后继续构建DOM。浏览器甚至会延迟脚本执行和构建DOM,直至完成其CSSOM的下载和构建。这就是所谓的JS阻塞页面。
- 现在可以在
script标签上增加属性defer或者async来改善。 - 浏览器会将脚本中改变
DOM和CSS的地方分别解析出来,追加到DOM树和CSSOM规则树上。 - 所以,
script标签的位置很重要。
CSS阻塞渲染: 页面是通过渲染树绘制的,渲染树的生成又必须等所有的CSS(内联、内部和外部)都已经下载完,并解析完生成CSSDOM。这就是CSS阻塞渲染。
CSS阻塞渲染意味着,在CSSOM完备前,页面将一直处理白屏状态,这就是为什么样式放在head中,仅仅是为了更早的解析CSS,保证更快的首次渲染。- 需要注意的是,即便你没有给页面任何的样式声明,
CSSOM依然会生成,默认生成的CSSOM自带浏览器默认样式。
优化建议
关键是要深入理解浏览器渲染流程,合法的书写 HTML ,CSS,JS。
减少JS阻塞
- 合理运用
defer或者async。 - 在
domContentLoaded或者onload事件触发时,通过动态创建script标签的方式引入js文件。 - 合理运用缓存策略。
- 要避免过多
JS请求,也要避免单个JS过大。
减少CSS阻塞
- 样式尽量前置(放
head标签),尽早解析生成CSSDOM。 - 样式精简,嵌套层级最小化。
减少重绘
- 合法,合理书写
Html布局是基础,避免无用的深层嵌套。 - 减少 或者 合并
Dom操作,读/写操作尽量放一起。 - 通过
document对象的createDocumentFragment()``cloneNode()方法创建离线Dom,完成操作后再用于真实Dom。 window.requestAnimationFrame()进行动画优化。
参考资料
从浏览器多进程到JS单线程
setTimeout和requestAnimationFrame
浏览器渲染原理与过程
DOMContentLoaded 与 load事件
浅谈 JS Event Loop 机制
JS引擎(V8为例)
`JavaScirpt 引擎主要用来将 JS 代码编译为不同 CPU(Intel, ARM 以及 MIPS 等)能识别的对应的汇编代码。同时,JavaScript 引擎的工作也不只是编译代码,它还要负责执行代码、分配内存以及垃圾回收。
最出名的JS引擎当属 Google V8。
V8 引擎是用 C ++ 编写的开源高性能 JavaScript 和 WebAssembly 引擎,它已被用于 Chrome 和 Node.js 等。 V8 是一个可以独立运行的模块,完全可以嵌入到任何 C ++应用程序中,比如 Node。
V8 是一个非常复杂的项目,有超过 100 万行 C++代码。它由许多子模块构成,其中最重要的 4 个模块是:
- Parser:负责将 JavaScript 源码转换为 Abstract Syntax Tree (AST)
- Ignition:interpreter,解释器,负责将 AST 转换为 Bytecode,解释执行 Bytecode;同时收集 TurboFan 优化编译所需的信息,比如函数参数的类型。
- TurboFan:compiler,即编译器,利用 Ignitio 所收集的类型信息,将 Bytecode 转换为优化的汇编代码;
- Orinoco:garbage collector,垃圾回收模块,负责将程序不再需要的内存空间回收。

总结下来就是:Parser 将 JS 源码转换为 AST,然后 Ignition 将 AST 转换为 Bytecode,最后 TurboFan 将 Bytecode 转换为经过优化的 Machine Code(实际上是汇编代码)。
在 V8 出现之前,所有的 JavaScript 虚拟机所采用的都是解释执行的方式,这是 JavaScript 执行速度过慢的一个主要原因。而 V8 率先引入了即时编译(JIT)的双轮驱动的设计(混合使用编译器和解释器的技术),这是一种权衡策略,混合编译执行和解释执行这两种手段,给 JavaScript 的执行速度带来了极大的提升。
即时编译(Just-in-time compilation),简称为 JIT。指可以直接执行源码(比如:node test.js),但是在运行的时候先编译再执行,这种方式被称为JIT。V8 也属于 JIT 编译器。
解释执行和编译执行都有各自的优缺点,解释执行启动速度快,但是执行时速度慢,而编译执行启动速度慢,但是执行速度快。为了充分地利用解释执行和编译执行的优点,规避其缺点,V8 采用了一种权衡策略,在启动过程中采用了解释执行的策略,但是如果某段代码的执行频率超过一个值,那么 V8 就会采用优化编译器将其编译成执行效率更加高效的机器代码。
V8 执行一段 JavaScript 代码所经历的主要流程可总结为:
- 初始化基础环境;
- 解析源码生成 AST 和作用域;
- 依据 AST 和作用域生成字节码;
- 解释执行字节码;
- 监听热点代码;
- 优化热点代码为二进制的机器代码;
- 反优化生成的二进制机器代码。
V8 有对应的 D8工具。它是一个非常有用的调试工具,你可以把它看成是 debug for V8 的缩写。我们可以使用 d8 来查看 V8 在执行 JavaScript 过程中的各种中间数据,比如作用域、AST、字节码、优化的二进制代码、垃圾回收的状态,还可以使用 d8 提供的私有 API 查看一些内部信息。
此外,V8引擎内部还做了一系列优化措施:
- 惰性解析基础上,增加预解析器来解决了闭包所带来的外部变量无法释放的问题。
- 引入快属性,慢属性机制,提升对象属性的访问速度。
- 通过内联缓存来提升函数执行效率。
- 引入字节码,相对二进制码,降低了时间和空间成本。
具体优化细节可参考下面文献:浏览器是如何工作的:Chrome V8让你更懂JavaScript
下面,我们主要探究一下JS的异步代码处理机制。
JS异步
- 我们都知道,
JS引擎 是单线程设计。它的创造者就是单纯为了keep it simple。 - 我们也知道,
JS代码可以分为同步代码和异步代码。
常见的 异步代码 生产者有:
seTimeoutsetIntervalDom事件ajax/fetch请求process.nextTick(Nodejs特有)等
处理 异步代码 的方式有:
callBackpromiseasync/wait- 发布/订阅 (观察者模式)
为了异步处理一些耗时的操作,JS引擎又是基于 事件循环(Event Loop)机制(单独的事件触发线程处理),实现 非阻塞I/O的。那么,Event Loop 机制如何工作呢:
JS将执行环境分为执行栈和任务队列。首先,当前代码块所有代码被放到
执行栈中 自上而下 执行;当遇到异步操作,将异步
API中定义的 回调函数 作为任务,添加到任务队列中;当
执行栈中的同步代码全部执行完,处于空闲态后,会去循环处理任务队列里的任务;将
任务队列里的任务按先来后到的顺序依次放到执行栈中执行。当
任务代码中遇到异步代码,再次放入任务队列;如此往复,称为
事件循环(Event Loop);
注意:
熟悉
Promise原理就会很清楚:Promise构造函数代码是同步代码。异步是体现在then和catch块中。在
async/await中,await出现之前的代码也是立即执行的同步代码。之后的代码是放入任务队列的异步代码。
// async/await 本身就是promise+generator的语法糖。
async function async1() {
console.log('async1 start');
await async2();
console.log('async1 end');
}
//等价于
function async1() {
console.log('async1 start');
Promise.resolve(async2()).then(() => {
console.log('async1 end');
})
}另外,任务队列 中的 异步任务 又分为 宏任务 和微任务
宏任务
宏任务(macrotask),也叫tasks。以下 异步任务产生的回调会被放入 宏任务 队列:
setTimeoutsetIntervalI/O操作UI rendering(浏览器独有)requestAnimationFrame(浏览器独有)setImmediate(Node独有)
微任务
微任务(microtask),也叫jobs。以下 异步任务 会被放入 微任务队列:
Promiseasync/awaitMutationObserverwindow.queueMicrotask()process.nextTick(Node独有)
MutationObserver: 一个用来监视DOM变动的API。DOM的任何变动,比如节点的增减、属性的变动、文本内容的变动,这个API都可以得到通知。了解更多)
queueMicrotask(): 为了允许第三方库、框架、polyfills 能使用微任务,Window 暴露了 queueMicrotask() 方法。
下面,我们来看看 分 宏任务队列 和 微任务队列 的Event Loop 执行顺序:
所有代码被放到
执行栈中 自上而下 执行;遇到 异步操作
API,根据API的类型, 将 回调函数 添加到任务队列中宏任务队列或者微任务队列;当
执行栈中的 同步代码 全部执行完,处于空闲态后,先去循环微任务队列里的函数;依次将
微任务队列里的函数 放到执行栈中执行,如果过程中产生新的微任务,也会放入微任务队列的末尾,并且在此次循环中执行完成。当
微任务队列里的函数全部执行完成,才会将宏任务队列里的函数按顺序放到执行栈中执行。当执行完当前的
宏任务时,只有当微任务队列为空的时候,才会继续执行下一个宏任务。也就是说,在执行宏任务的时候产生了新的微任务,那么在这个宏任务执行完成以后,依然优先处理微任务。如此往复。直到所有
任务队列为空。
重要:每一个宏任务执行完毕,会检查渲染任务列表,如果有渲染任务,
GUI线程会接管渲染,渲染完成后,JS线程继续接管。
Nodejs 有所不同
NodeJS的 异步操作 也分宏任务和微任务。宏任务分为 6 个阶段,4个队列。微任务分为 2 个队列。
宏任务
6个阶段:
timers阶段:这个阶段执行setTimeout和setInterval设置的callback。I/O callback阶段:执行[close事件、timers、setImmediate()] 设定的callbacks之外的其他callbacks。idle, prepare阶段:仅node内部使用。poll阶段:获取新的I/O事件,适当的条件下node将阻塞在这里。check阶段:执行setImmediate()设定的callbacks。close阶段:执行socket.on('close', ....)这些callbacks。
4个队列:
iTimers:setTimeout,setIntervaliIO Callbacks:other……iCheck:setImmediate()iClose:socket.on('close', ....)
微任务
2个队列
Next Tick:是放置process.nextTick(callback)的回调任务.Other Micro:放置其他微任务,比如Promise等。
Node.js 中的 EventLoop 过程
NodeJS 11 之前:
- 执行全局
Script的同步代码。 - 执行
微任务,先执行所有Next Tick Queue中的所有任务,再执行Other Microtask Queue中的所有任务。 - 开始执行
宏任务,共6个阶段,从第1个阶段开始执行。每一个阶段的宏任务全部 执行完成后,回去执行所有微任务(同上),再执行 下个阶段 的全部宏任务。 - 这就是
NodeJs的Event Loop。
Node 11 +的变化:
宏任务还是分阶段依次执行,但是每一个阶段的每一个
宏任务执行完,都回去执行所有微任务,再继续执行下一个宏任务。而不是等每个阶段宏任务全部执行完才回去执行微任务。和浏览器更加趋同.
执行顺序自测
浏览器端输出顺序:
async function async1() {
console.log('async1 start');
await async2();
console.log('async1 end');
}
async function async2() {
console.log('async2');
}
console.log('script start');
setTimeout(function() {
console.log('setTimeout');
}, 0)
async1();
new Promise(function(resolve) {
console.log('promise1');
resolve();
}).then(function() {
console.log('promise2');
});
console.log('script end');
/*
script start
async1 start
async2
promise1
script end
async1 end
promise2
setTimeout
*/NodeJS中输出顺序:
console.log(1);
setTimeout(() => {
console.log(2);
process.nextTick(() => {
console.log(3);
});
new Promise((resolve) => {
console.log(4);
resolve();
}).then(() => {
console.log(5);
});
});
new Promise((resolve) => {
console.log(7);
resolve();
}).then(() => {
console.log(8);
});
process.nextTick(() => {
console.log(6);
});
setTimeout(() => {
console.log(9);
process.nextTick(() => {
console.log(10);
});
new Promise((resolve) => {
console.log(11);
resolve();
}).then(() => {
console.log(12);
});
});
//node <11: 1 7 6 8 2 4 9 11 3 10 5 12
// node>=11: 1 7 6 8 2 4 3 5 9 11 10 12参考文档
排序算法
几个概念
- 时间复杂度:执行算法所需要的计算工作量。
- 空间复杂度:算法在运行过程中临时占用存储空间大小的度量。
- 稳定性:如果存在多个具有相同的记录,若经过排序,这些记录的相对次序保持不变,则称这种排序算法是稳定的;否则称为不稳定的。
in-place算法,指的是不需要额外空间的算法。
算法的时间复杂度和空间复杂度是可以相互转化的。比如谷歌浏览器相比于其他的浏览器,运行速度要快。是因为它占用了更多的内存空间,以空间换取了时间。
如何选择
- 若n较小(如 n≤ 50),可采用 直接插入或直接选择排序。
- 若n较大,则应采用时间复杂度为O(nlgn)的排序方法:快速排序、或归并排序。
- 快速排序是目前内部排序中被认为是最好的方法,当待排序的关键字是随机分布时,快速排序的平均时间最短;
- 若要求排序稳定,则可选用归并排序。先利用直接插入排序获的有序子序列,然后再两两归并。因为直接插入排序是稳定的,所以改进后的归并排序仍是稳定的。
Array.sort()使用的是直接插入排序和快速排序结合的排序算法。数组长度不超过10时,使用直接插入排序。长度超过10使用快速排序。
冒泡排序
- 思想:相邻两个数比较大小,较大的数下沉,较小的数冒起来。
- 时间复杂度
O(n2),一般不推荐使用。
function BubbleSort(arr){
let temp; //临时变量
for(var i = 0; i < arr.length-1; i++){
let flag = false
for(var j = arr.length-1; j > i; j--){
if(arr[j] < arr[j-1]){
temp = arr[j];
arr[j] = arr[j-1];
arr[j-1] = temp;
flag = true
}
}
if(!flag) break; // 如果第N次遍历没有发生交换,说明已经排序完成,无需后续的遍历,提升了排序稳定性。
}
return arr
}直接选择排序
- 思想:初始时在序列中找到最小(大)元素,放到序列的起始位置作为已排序序列;然后,再从剩余未排序元素中继续寻找最小(大)元素,放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
- 时间复杂度
O(n2),数据量较小时推荐。 - 不稳定排序。比如序列:
{ 5, 8, 5, 2, 9 },首次选择以后,最小元素2和第一个5进行交换,从而改变了两个元素5的相对次序。
function SelectionSort(arr)
{
for (let i = 0; i < arr.length - 1; i++){
let min = i, temp;
for (let j = i + 1; j < arr.length; j++){
if (arr[j] < arr[min])
{
min = j;
}
}
if (min != i)
{
temp = arr[min];
arr[min] = arr[i];
arr[i] = temp;
}
}
return arr;
}
直接插入排序
- 思想:和抓扑克牌类似,首个元素为初始已排序队列,第二个元素从后往前扫描已排序队列,找到合适的位置插入,后面的元素依此类推。
- 特点:时间复杂度
O(n2), 通常在数据量级较小时使用。Array.sort()内部,在数组长度不超过10时,就使用插入排序。是稳定排序算法。
function insertSort(arr){
let temp, lenth = arr.length;
for(let i =0 ; i < lenth-1 ; i++){
for(let j = i + 1 ; j > 0 ; j--){
if(arr[j] < arr[j-1]){
temp = arr[j-1];
arr[j-1] = arr[j];
arr[j] = temp;
}else{ //不需要交换
break;
}
}
}
return arr;
}快速排序
- 思想:分而治之。先从数列中取出一个数作为基数(一般是第一个或者最后一个);将比这个数小的全部放在它的左边,大于或等于它的全部放在它的右边;对左右两个小数列重复第二步,直至各区间只有1个数。
- 特点:平均时间复杂度:
O(N*logN)O(N*logN), 通常明显比其他O(nlogn)算法更快。快速排序是不稳定的排序算法。
function quickSort(arr) {
if (arr.length <= 1)
return arr;
// 首个元素作为基数
const pivot = arr[0];
//左右区间,用于存放排序后的数
let left = [], right = [];
for (let i = 1; i < arr.length; i++) {
if (arr[i] < pivot) {
left.push(arr[i]);
} else {
right.push(arr[i]);
}
}
//递归left/right; 使用concat操作符,将左区间,基准,右区间拼接为一个新数组
return quickSort(left).concat([pivot], quickSort(right));
}归并排序
- 思想:归并排序主要依赖归并(Merge)操作。指的是将两个已经排序的序列合并成一个序列的操作。
- 特点:平均时间复杂度 O(NlogN)。是稳定排序算法。
下面,我们应用归并排序思想,合并一个二维有序数组成一维有序数组:
/**
* 基本思路:双指针 从头到尾比较两个数组的第一个值,根据值的大小依次插入到新的数组中
* @param {Array} arr1
* @param {Array} arr2
*/
function merge(arr1, arr2){
let result=[];
while(arr1.length>0 && arr2.length>0){
if(arr1[0]<arr2[0]){
/*shift()方法用于把数组的第一个元素从其中删除,并返回第一个元素的值。*/
result.push(arr1.shift());
}else{
result.push(arr2.shift());
}
}
return result.concat(arr1).concat(arr2);
}
function mergeSort(arr){
let lengthArr = arr.length;
if(lengthArr === 0){
return [];
}
while(arr.length > 1){
let arrayItem1 = arr.shift();
let arrayItem2 = arr.shift();
let mergeArr = merge(arrayItem1, arrayItem2);
arr.push(mergeArr);
}
return arr[0];
}
let arr = [[1,2,3],[4,5,6],[7,8,9],[1,2,3],[4,5,6]];
mergeSort(arr);参考资料
数据平均分组算法的一点思考
比如,有一堆整数要分为 N 组,确保每一组尽量相等。这是我看到的一个面试题,觉得这种算法在某些公司的实际项目中应该是有应用场景的。所以就研究一下。
一点思路
- 等分如何衡量:
标准差。 - 常识性做法,从大到小开始分。
- 分配标准:根据平均值判断。我们知道,基本上没有每组刚好都等于平均值的情况,普遍的情况是均衡分布在平均值上下。所以平均值也需要浮动。
/**
* @intArr 整数数组
* @count 分组数目
* @float 平均值浮动阈值(核心)
*/
function groupIntArr( intArr = [], count = 1, float = 1) {
// 容错略 。。。
// 数组从大到小排序
intArr.sort((a,b) => b - a);
//计算平均值
let avg = intArr.reduce((a,b) => a + b) / count;
let sum = 0; // 临时总和 用于和平均值判断
let resArr = new Array(count) // 初始化
for(var i = 0; i < count -1; i ++) { // 为啥是 count-1 :最后一个分组直接赋予剩余list
resArr[i] = [intArr[0]];
sum = intArr[0];
intArr.shift(); // 记得从原数组删除
// 这里一定要加 “=” ;float 是关键
for (var j = 0; j < intArr.length ; j++) {
if (sum + intArr[j] <= avg + float) {
resArr[i].push(intArr[j]);
sum += intArr[j];
intArr.splice(j,1); //放入结果数组,就从原数组删除
}
}
}
resArr[count -1] = intArr;
// 打点日志
const sumArr = []
resArr.forEach( (item) => {
sumArr.push(item.reduce((a,b) => {return a + b}));
})
console.log('平均数:', avg)
console.log('分组总和:', sumArr.join(','));
return resArr
}
/*** 执行 **/
groupIntArr([11,42,23,4,5,6,4,5,6,11,23,42,56,78,90],3,1)
//[90, 42, 4] [78, 42, 11, 4] [56, 23, 23, 11, 6, 6, 5, 5]
// [90, 42, 4]
// [78, 56]
// [42, 23, 23, 11, 11, 6, 6, 5, 5, 4]
// 平均数: 135.33333333333334
// 分组总和: 136,134,136 (标准差:1.1547)
groupIntArr([11,42,23,4,5,6,4,5,6,11,23,42,56,78,90],3,0)
// 平均数: 135.33333333333334
// 分组总和: 132,134,140 (标准差:4.16333)
groupIntArr([11,42,23,4,5,6,4,5,6,11,23,42,56,78,90],3,2)
// 平均数: 135.33333333333334
// 分组总和: 137,134,135 (标准差:1.52753)
groupIntArr([1100,4200,2300,400,500,600,400,500,600,1100,2300,4200,5600,7800,9000],3)
// 平均数: 13533.333333333334
// 分组总和: 13200,13400,14000 (标准差:416.3332)
groupIntArr([1100,4200,2300,400,500,600,400,500,600,1100,2300,4200,5600,7800,9000],3, 100)
// 平均数: 13533.333333333334
// 分组总和: 13600,13400,13600 (标准差:115.47005)- 主逻辑:先从大到小排序,从最大的开始分组,然后在不超过数据平均值的情况下逐个分组,最后一个分组直接使用剩余数据。
- 核心:通过
float控制平均值的浮动可以得到更完美的结果,所以关键就是根据实际数据的情况,选择合适的float(比如上述代码中,小数据数组float = 1更适配,大数据数组float = 100更适配 )。
如果要追求极致,可以通过设置多个
float值甚至一个区间,然后通过判断所有结果的标准差来获取到最优分组。但是这样时间复杂度和空间复杂度就很高了。
《2020前端现状调查报告》学习

概述
作者对来源于世界各地的 4500 位前端开发进行了问卷调查。根据采集到的数据进行了一系列有趣的图表统计。
报告分 11 个章节,分别邀请了相关权威的技术人士根据调查结果进行分析,并运用他们令人钦佩的专业知识和大局观进行了总结。

本想完整翻译这份报告,但是发现 github 上已经有团队在讨论翻译中。这里,我主要就报告核心内容进行一些精炼和总结,外加那些有趣的图表。
开发者(developers)
大多数参与调查的开发者都是从事前端开发 3 年以上的 高级+ 前端。



框架(Frameworks)
现状:
React 绝对王者。有 74.2% 的调查对象在使用 React ,超过 Angular 和 Vue 用户的总和。
大家对 Angular 的相对兴趣有所下降,对 Vue 的兴趣增长也有些停滞。更新较慢是部分原因。
有趣的一点是:jQuery 虽然很少被提及,但它仍然是网络上部署最广泛的 JavaScript 库。
在状态管理方面,使用 React Context API 和 hooks(49.6%)的人比使用 Redux (48.2%)的人更多。
趋势:
新一代响应式框架(Reactive Frameworks)快速崛起, 或将成为 React 生态的可替代品。这和 TypeScript 的流行也有很大关系。
大家对新一代响应式框架也产生了浓厚的兴趣,比如 Svelte ,它致力于在普通 DOM 结构之上提供响应式。
另一个竞争者是 Stencil.js, 一个专注于网络组件(web component)的框架,和 Svelte 一样,专注于高效的编译。
多数人更喜欢 TypeScript,77.2% 的受访者已经在使用 TypeScript 。因此,很多现有框架正在改善对 TypeScript 的支持,而且许多框架开始在内部使用 TypeScript。
一点争议:目前,新一代框架可能非常适合小型应用,但在构建大型应用时需要更多的工作。的确,因为它们没有像框架那样需要支持过去几年的功能的遗留问题,所以默认的包很小。但是,它们也非常符合现代标准和语言特性。






托管(Hosting)
44.3% 的受访者仍在将他们的应用部署到自己的 Web 服务器上。这提醒我们,传统DC仍有巨大的市场,公有云仍有很多发展机会。
在云服务提供商中,亚马逊云计算服务 AWS(Amazon Web Services)最受欢迎(38.7%)。
Netlify 拥有很高的渗透率 (23.3%),高于 GCP(Google Cloud Platform) 和 Microsoft Azure。这是其自身优质能力的体现。
前端开发的未来需要 Netlify 和 Vercel 这样的平台,它们专注于为前端团队提供易于使用且功能强大的后端基础设施的抽象。自成一派,并不断成长。





JAMstack
近1/3的受访者最近建立了一个 Jamstack(JavaScript、API、Markup)网站。另外,让我个人感到高兴的是,其中超过一半的人使用了 Next.js –我们在 Vercel 为 Jamstack 创建的 React 框架。预计在接下来的几个月里,建设 Jamstack 网站的前端开发者的比例会更大。
对我来说,Jamstack 的魅力在于它让我们做得更少,完成得更多。有了 Jamstack ,你不需要在每次请求时渲染一个页面(SSR服务器端渲染),而是在请求时间之前预渲染一个页面(静态生成)。这可以被 CDN 上的所有边缘节点共享,以获得最佳性能、更高的可用性、更低的成本和零维护开销。
此外,Jamstack 框架也在不断发展,超越静态,采用动态的灵活性。例如,Next.js 允许你在生产构建后静态生成额外的页面或重新生成现有的页面(增量静态生成)。即使你的应用程序有数百万个页面,初始构建也会立即完成,因为这些页面可以增量生成。
可重用的 API(Jamstack中的 "A")也在崛起。现在市场上有很多无头内容管理系统 (Handless CMS)、无头电商(headless e-commerce)、无头身份(headless identity) 等供应商。难怪框架也在随着这些趋势发展。经验之谈: Next.js 有预览模式功能,当你在 Handless CMS 上预览页面时,可以有条件地绕过静态生成。
受访者正在使用各种各样的 Jamstack 解决方案,正在尝试不同的想法。这也推动了Jamstack社区的发展,使其成为一个更简单、更高性能的网络。
Edge CDN的Anycast网络可以缓存边缘的静态内容,通过尽可能接近访问者的资源来减少延迟,从而提高用户访问速度。
Handless CMS:Handless content management system,是一种没有前端组件的系统,内容可以通过API发布到任何地放的方式展示给最终用户。


微前端(Micro frontends)
已经有 1/4 的前端开发开始构建自己的微前端项目。
网络组件(Web component)是很好的,入门级的 微前端 解决方案。
有不少新的微前端框架,既支持后端渲染又具备前端构造(比如Holocron, Podium,Ara Framework。这些框架是对微前端社区的巨大补充,但切记谨慎挑选–始终要契合你的应用环境。
只有20%的调查者认为微前端可能会在未来三年内消失。Luca Mezzalira认为,微前端现在还处于早期,有很多经验教训需要学习,但他相信微前端会不断发展并达到成熟–就像微服务一样。
TC39/Realms提案已经进入stage 2阶段, Luca Mezzalira认为这将为微前端打开新的局面。
微前端并不是万能的,但绝对是对其他架构(比如 SSR、JamStack 和 SPA )的一个很好的补充。 只要在合适的场景应用,将事半功倍。
Luca Mezzalira:DAZN架构副总裁,"Building Micro-Frontends"作者。
TC39是Ecma International标准化组织旗下的技术委员会的一员,它负责管理ECMAScript语言和标准化API。
Realms提案提供了一种新的机制,用于在一个新的全局对象和一组JavaScript内置的上下文中执行JavaScript代码。


SEO
搜索引擎优化(Search Engine Optimization)- SEO 对任何在线业务都至关重要。
高达 52% 的调查者并不关心 SEO ,可能许多调查者开发的是受密码权限控制的应用。
做好 SEO ,首先应该确保搜索引擎能够正确地在你的网站上渲染 JavaScript。不小心在 robots.txt 中屏蔽了一些脚本,或者使用了搜索引擎抓取工具(比如 Googlebot 百度蜘蛛)不支持的 JavaScript 功能,都会影响 SEO。
渲染只是 SEO 众多方面中的一个。你必须把注意力放在使用正确的 HTML 标签和设计一个合理的网站结构上。就像你在服务器端渲染、客户端渲染和动态渲染之间选择一样。关键是要理解搜索引擎的工作原理。
robots.txt是一个协议,而不是一个命令。robots.txt是搜索引擎中访问网站的时候要查看的第一个文件。robots.txt文件告诉蜘蛛程序在服务器上什么文件是可以被查看的。建议当您的网站包含不希望被搜索引擎收录的内容时,才需要使用robots.txt文件。如果希望搜索引擎收录网站上所有内容,请勿建立robots.txt文件。


应用程序可访问性(Application accessibility)
这是一个关乎用户体验的话题,对于非常接近用户的前端开发来说,是非常重要的。
作为前端开发人员,我们经常是这项工作流中最后一个提升可访问性的人。要摆脱这种模式,我们需要转变思维。我们必须努力成为同行的好老师,做好规范,榜样,保证可访问性不会取决于我们开发者的时候,网站才能为每个人服务。
关心无障碍的开发人员似乎大多数都熟悉《web内容无障碍指南》(WCAG)的基础。在未来,我们也应该尝试了解有多少人测试无障碍性。现在自动测试无障碍性的工具越来越多。


开发团队
92% 的受访者表示他们在过去一年中曾作为开发团队的一员工作过。
前端架构和部署基础设施的最新趋势已经影响了前端开发人员与团队成员协作的方式。
随着新的前端架构(如 Jamstack )的兴起,前端开发人员可以独立于后端部署前端。他们不再需要等待完整的后端测试套件的运行,从而导致更快的迭代。
现成的后端 API ( 如 headless CMS、IDP 等) 越来越多,可以很容易地插入到你的前端。这使得后端开发人员能够更加专注于开发业务特有的 API。
我们开始与设计师和产品负责人更多的打交道。因为 Jamstack 应用程序可以快速、廉价地部署到 CDN edge 上,所以可以为每个分支和每个提交分配一个唯一的“预览” URL。我们已经在 Vercel 做到了这一点——现在,设计人员和产品所有者只需点击预览 URL,就可以立即查看前端开发人员所做的更改是否符合预期。这比分享截图和 gif 更有效。
最后看软件测试。随着 puppeteer 的引入,Chrome 的无头 web 浏览器,结合无服务器计算,端到端测试变的快速和廉价。例如,您可以让运行 Checkly + puppeteer 测试案例(由QA专家编写) 这样的服务和预览 URL 对应起来。此外,随着 Vercel 和其他前端部署平台的崛起,DevOps 工程师可以花更少的时间来支持前端开发人员。
IDP: (identity provider)身份提供者,是一个系统组件,它能够向终端用户或连接到互联网的设备提供一组登录凭据,以确保实体是谁或它所说的是什么,跨越多个平台、应用程序和网络。例如,当第三方网站提示终端用户使用微信帐户登录时,微信登录就是身份提供者。
Puppeteer: 一个控制headless Chrome的Node.js API。它是一个Node.js库,通过DevTools协议提供了一个高级的API来控制headless Chrome。
Checkly是一款验证API端点正确性和浏览器点击流的监控工具。Checkly可以使用Puppeteer框架进行自动化浏览器操作。


设计
让设计师与开发者紧密合作不再是一种时尚,而是一种标准。我们已经有了非常好的工具让这种合作变得更好。
软件开发公司有两种设计人员——以用户为中心的UX/UI设计人员和以业务为中心的产品设计人员——已经成为一种标准。
随着产品设计师的加入,软件公司越来越多地关注于创建与客户业务目标相匹配的战略和产品。
产品设计师的出现这意味着,作为软件公司,我们越来越多地关注客户的真实需求,致力于创建与他们的业务目标相匹配的战略和产品。
为了使这种合作富有成效,我们需要更好的工具,比如 Figma, InVision, Sketch和Zeplin。71.7%的开发团队已经使用了这类工具。


质量保证
如今,越来越多的数字产品的功能是在客户端实现的。这使得软件工程师和QA专家必须将测试作为开发、维护和扩展JavaScript应用程序的工作流程的一部分。可喜的是,80%的前端开发者已经开始进行软件测试,而且这一数字在过去几年里还在不断增长。
软件测试与现代前端开发是密不可分的。
软件测试是对数字产品稳定性的必要投资,最终提高了我们整个工作流程的生产力。我们相信Capybara、RSpec、Ember CLI和QUnit等工具可以进行单元测试、集成测试和端到端测试。当然,还有更多的解决方案供你选择。
在.cult,我们相信测试工具生态系统的持续增长将很快允许我们通过自动化覆盖产品开发工作流的更大一部分。



前端未来趋势
我们对调查结果和最近前端web开发的变化无不惊讶。所以预测前端的未来不是一件容易的事。
然而,在前端开发社区,爱与恨之间的界限很窄。一两年前,Redux是配合React进行状态管理的普遍选择。但前端开发人员现在厌倦了Redux 所带来的问题,并迅速加入 React hooks 的行列。现在使用 hooks 的用户已经超过了 Redux ,有 34% 的前端开发者认为 Redux 将在 3 年后消失。
同时,前端开发的世界也变得越来越复杂。同样,一两年前,像持续集成和容器化这样的解决方案更多地被认为是后端事物。前端开发人员现在意识到,他们也可以从这些解决方案中受益。现在,77% 的前端开发者使用 CI , 62% 使用容器。它们已经成为前端开发的新标准。
那么,在接下来的 12 个月里,前端会发生怎样的变化呢? Svelte 会成为3个最流行的框架之一吗? 微前端会成熟吗? 没有人能确定,但在我看来,有一件事是确定的: 我们会对一些变化的发生速度感到惊讶。让我们期待《2021年前沿状态》报告。

原文&拓展文档
报告原文
Netlity官网
Jamstack网
[GatsbyJs中文网] (https://www.gatsbyjs.cn/)
WCAG
MongoDb安装配置
下载
可以直接到mongoDB官网下载安装包。
我们公司对软件安装有限制,没有管理员权限。所以我下载的免安装的,解压即用的mongo
$ sudo curl -O https://fastdl.mongodb.org/osx/mongodb-macos-x86_64-4.4.2.tgz #下载
$ sudo tar -zxvf mongodb-osx-ssl-x86_64-4.4.2.tgz # 解压
安装&配置
- 对于
tgz文件,直接拷贝到全局目录/usr/local/,然后配置环境变量即可。建议将文件夹命名为mongodb。 /usr/local为隐藏目录,正常在finder中是看不到的,需要在finder中按shift + command +G输入/usr/local并点击前往。
命令行操作如下:
# 安装(copy)
$ sudo cp -r mongodb-osx-x86_64-4.4.2/ /usr/local/
$ sudo mv mongodb-osx-x86_64-4.4.2/ mongodb
# 配置环境变量
$ vi ~/.bash_profile # 增加: export PATH=$PATH:/usr/local/mongodb/bin
$ source .bash_profile
不幸的是,我们公司系统有管理员权限控制,是无法使用全局目录/usr/local/ 的。所以,我使用的自己的工作目录:
# 安装(copy)
$ sudo cp -r mongodb-osx-x86_64-4.4.2/ /Users/myself
$ sudo mv mongodb-osx-x86_64-4.4.2/ mongodb
# 配置环境变量
$ vi ~/.bash_profile # 增加: export PATH=$PATH:/Users/myself /mongodb/bin
$ source .bash_profile验证安装是否ok:
$ mongod -version # 正常打印出mongo版本信息,即安装生效。启动mongodb
启动之前,我们需要创建db(数据存储)和logs(日志文件)的文件夹。可以直接创建在安装的mongodb目录,也可以放到单独的目录。
$ cd /Users/myself
$ mkdir mongoData # 创建单独目录
$ cd mongoData
$ mkdir db
$ mkdir logs启动mongodb
# 常用命令
$ mongod --dbpath data --logpath logs/m.log --logappend
# --dbpath 指定数据文件夹
# --logpath 指定日志存储文件
# --logappend 后台运行明显的,启动mongodb是有一系列配置的。所以,通常我们会设置一个单独的配置文件,根据配置文件来启动mongodb。
$ cd /User/myself/mongoData
$ vi m.conf # 增加配置文件
# 常用配置如下:
bind_ip_all = true # 任何机器可以连接
#bind_ip = 127.0.0.1,192.168.0.3 # 本机和192.168.0.3可以访问
port = 27017 # 实例运行在27017端口(默认)
dbpath = /Users/myself/mongoData/db # 数据文件夹存放地址(db要预先创建)
logpath = /Users/myself/mongoData/logs/m.log # 日志文件地址
logappend = false # 启动时 添加还是重写日志文件
fork = true # 是否后台运行
#auth = true # 开启校验用户
# 启动mongodb
$ mongod -f m.conf如果没有什么报错信息,基本上mongodb已经启动
连接mongodb
在新的终端中输入”mongo” 连接数据库,如果出现数据库操作符>, 那么恭喜你,可以使用mongodb了。
$ mongo
MongoDB shell version v4.4.2
connecting to: mongodb://127.0.0.1:27017/?compressors=disabled&gssapiServiceName=mongodb
Implicit session: session { "id" : UUID("92e4a9f7-b622-4a1a-9de1-df4cc8e1b581") }
MongoDB server version: 4.4.2
# ...略
> 1+1
2
> Nodejs + mongodb
在Node项目中,我们可以使用Mongoose库来连接和使用mongodb。Mongoose是在node.js异步环境下对mongodb进行便捷操作的对象模型工具。
const mongoose = require('mongoose'),
/**
* 连接
*/
mongoose.connect('mongodb://127.0.0.1:27017/test', { useNewUrlParser: true });
/**
* 连接成功
*/
mongoose.connection.on('connected', function () {
console.log('Mongoose connection open to ' + DB_URL);
});
/**
* 连接异常
*/
mongoose.connection.on('error',function (err) {
console.log('Mongoose connection error: ' + err);
});
/**
* 连接断开
*/
mongoose.connection.on('disconnected', function () {
console.log('Mongoose connection disconnected');
}); 具体数据库操作,可参考mongoose官方文档。
浅谈前端配置化
源自共享
我觉得配置化来源于共享,是为了更好的实现共享化。
为了提升开发效率,我们通过对代码的封装,抽象出一系列可共享的单元。合理的封装大大的降低了代码冗余,从而提升了系统的性能和可维护性。
不过,不能追求共享的极致,如果封装过多,拆分过细反而会降低可维护性。
同时,共享离不开配置。小到一个组件,大到一个页面/项目,我们都是通过支持配置不同的参数来实现共享的目的。
配置化细分
- 组件级别的配置:主要是合理的设计参数,使之覆盖多个场景,并具有可拓展性。
- 页面级别的配置:
Url参数算一种,但是对于较复杂的配置,可以使用单独的js/json配置文件。 - 项目级别的配置:比如云平台,初始化项目的脚手架。
组件级别
对于组件级别配置,不能过于臃肿。对于差异较大,对组件改造较大的场景,根据实际情况,可考虑通过以下方式实现:
- 直接私有定制。
- 抽象新的可共享组件。
- 基于原有共享组件二次封装。
项目级别
SaaS云平台 可能是当前最完美的项目/系统级别复用的技术场景了。
脚手架 算项目级别复用的一种配置化场景,通过 模版项目 + 配置文件 + 生成脚本,初始化一个项目。
云平台
云计算平台也称为云平台,是指基于硬件资源和软件资源的服务,提供计算、网络和存储能力。其根本其实也是为了共享。云平台服务主要分为以下三种:
- 基础架构即服务 (
IaaS) 是一种云计算产品,供应商为用户提供对服务器、存储和网络等计算资源的访问。组织可以在服务提供商的基础架构中使用自己的平台和应用。 - 平台即服务 (
PaaS) 是一种云计算产品,为用户提供云环境,用于开发、管理和交付应用。除存储器和其他计算资源以外,用户能够使用预构建工具套件,开发、定制和测试自己的应用。 - 软件即服务 (
SaaS) 是一种云计算产品,为用户提供对供应商云端软件的访问。用户无需在其本地设备上安装应用。相反,应用驻留在远程云网络中,通过 Web 或 API 进行访问。通过应用,用户可以存储和分析数据,并可进行项目协作。
页面级别
页面级别的配置化,当然也是为了实现页面级别的共享。根据配置化的程度或者方式,可以大致分为以下两种:
url参数:我们大部分url参数是为了在页面之间进行参数传递,但也有许多用于页面共享的场景。比如status,disabled这类参数,常用于编辑、查看、新增数据共享同一个页面。- 配置文件:
url参数只适用于一些简单的配置,如果一个页面需要配置的信息较多,最好创建单独的配置文件。
如果要使用配置文件,为了可维护性和可读性,还是需要制定一定的标准和规范,合理的设计配置文件。
配置文件一些建议:
- 使用 JSON schema这个国际公认标准。
- 配置场景分类,不同场景约定不同配置格式:比如 独立的功能模块 可以通过 switch(开关);
form表单:开源框架 formRender。
参考文献
前端多语言设计模式
前言
- 国际化背景下,前端系统需要支持多语言的场景越来越多。
- 当下已经存在开源的前端多语言解决方案(比如
i18n)。以React为例,多语言解决方案有i18n-reactreact-intl等。 - 不管是为了 合理运用 现有解决方案,还是针对自己公司的 特殊性 需要 二次封装,甚至完全 造轮子,了解 多语言设计模式 都很有必要。
思路
- 一套系统,支持多种语言,我们自然的会想到配置化。
N种语言N套配置;在页面加载的时候,根据当前语言环境,注入对应的语言配置文件。在业务组件中通过对应的API读取配置展示文案。
步骤
- 创建和管理多语言资源文件
- 根据语言(
key)获取资源文件 - 注入多语言资源文件并暴露调用的
API - 使用多语言
创建和管理多语言资源文件
- 创建:支持
N种语言,就配置N套对应的语言文件;通过{ key: value }的方式组织起来; - 粒度:为了扩展性和可维护性考虑,建议一个大的模块对应一套配置文件。对应特别通用的一些文案,可以配置一套公用配置文件。
- 管理:建议公用配置文件放顶层目录管理,模块配置文件放在模块目录一起管理。这样方便尽量只注入模块需要的配置文件。
//目录结构
.
|-- common
|-- locale
|-- en_US.json
|-- zh_CN.json
|-- pages
|-- moduleA
|-- public
|-- locale
|-- en_US.json
|-- zh_CN.json
|-- moduleB
|-- public
|-- locale
|-- en_US.json
|-- zh_CN.json
// 文件格式
{
"app.moduleA.hello_word": "Hello word",
"app.moduleA.hello_tom": "Hello tom"
...
}注入多语言资源文件并暴露调用的API
- 获取多语言
key:根据实际情况,一般来源有:navigator.userAgentnavigator.languageURL参数等。 - 顶层注入:封装多语言组件 (
LocalProvider) 包裹业务组件。
// 顶层注入的核心代码...
const lang = comFun.getLang(); // 获取当前环境语言的封装方法
ReactDom.render((
<LocalProvider lang={lang} files={
[
import('@common/locale/'+lang+'.json'), // 公共配置
import('./public/locale/'+lang+'.json') // 模块配置
]
}>
{/* AppContainer: 其他公共封装 */}
<Route path="/" component={AppContainer}>
<IndexRoute component ={Index}/>
<Route path="index" component={Index}/>
{/* ... */}
</Route>
</LocalProvider>
), document.getElementById('app'));
// LocalProvider 核心 & 简易实现...
import React, { Component } from 'react'
/**
* 多语言组件封装
*/
class LocaleProvider extends Component {
constructor(props) {
super(props)
const { files, lang } = this.props
this.Lang = lang
this.transObj = {}; //配置存储
this.state = {
localeReady: files && files.length ? false : true
}
this.translateFile(files, this.Lang)
}
/**
* 加载多语言文件
* @param {Array} imports 异步加载语言文件
* @param {String} lang 当前选择语言
*/
translateFile = (imports, lang) => {
if (imports && imports.length) {
Promise.all(imports)
.then(
modules => {
this.transObj = Object.assign({}, ...modules)
React.Component.prototype.T = this.$T // 方法注入
this.setState({ localeReady: true })
},
_ => {
console.log('require translate file fail')
}
)
.catch(e => {
console.error(e)
})
}
}
/**
* 读取多语言配置
* @param {String} key 具体配置的key
*/
$T = (key) => {
if (typeof key === 'string') {
return this.transObj[key] || key // 找不到key的配置 便返回key
} else {
throw new TypeError('Translate item should be string, but got ' +
typeof key)
}
}
render() {
return <div>{this.state.localeReady && this.props.children}</div>
}
}
export default LocaleProvider
以上只是粗糙的简易实现,实际项目中还需要进行扩展,润色,封装。比如增加文案的
format功能,可以插入变量。
使用多语言
// 略...
render() {
return (
<div>
{/* 直接调用 LocaleProvider 中注入 react.Component 中的方法 T 使用*/}
{ this.T('app.moduleA.hello_word')}
</div>
)
}注意:如果要在方法组件中使用,需要把
T作为props从Component父组件传递下去。也可以直接把文案作为props传递下去。
一些编程/算法题练习
温馨提示
以下纯属自我练习,可能不是最优解,甚至可能存在一些问题
写一个 mySetInterVal(fn, a, b),每次间隔 a,a+b,a+2b 的时间,然后写一个 myClear,停止上面的 mySetInterVal
function mySetInterVal(fn, a, b) {
let index = 0;
let timmer;
const loop = () => {
timmer = setTimeout( ()=> {
fn();
index++;
loop();
}, a + index*b );
};
loop();
return () => {
clearTimeout(timmer);
}
}
let testMyInt = mySetInterVal( () => { console.log('acc')}, 1000, 2000);斐波那契额数列
// 斐波那契额数列的公式表示
F(0) = 0;
F(1) = 1;
F(n) = F(n - 1) + F(n - 2);
// 递归实现
function fib(n) {
if(n < 0) throw new Error('输入的数字不能小于0');
if (n < 2) {
return n;
}
return fib(n - 1) + fib(n - 2);
}字符串出现的不重复最长长度
function lengthOfLongestSubstring(str) {
let result = '';
const strArr = str.split('');
for(let index = 0; index < str.length -1 ; index ++) {
let temp = strArr [index];
for(let cursor = index + 1 ; cursor < str.length; cursor++ ) {
if (temp.indexOf(strArr[cursor]) > -1 ) {
break;
} else {
temp += strArr[cursor]
}
}
if (temp.length > result.length ) {
result = temp;
}
}
return result;
}
lengthOfLongestSubstring("adfafwefffdasdcx");lodash._get 实现
function get(source, path, defaultValue = undefined) {
// a[3].b -> a.3.b -> [a,3,b]
// path 中也可能是数组的路径,全部转化成 . 运算符并组成数组
const paths = path.replace(/\[(\d+)\]/g, ".$1").split(".");
let result = source;
for (const p of paths) {
// 注意 null 与 undefined 取属性会报错,所以使用 Object 包装一下。
result = Object(result)[p];
if (result == undefined) {
return defaultValue;
}
}
return result;
}
// 测试用例
console.log(get({ a: null }, "a.b.c", 3)); // output: 3
console.log(get({ a: undefined }, "a", 3)); // output: 3
console.log(get({ a: null }, "a", 3)); // output: 3
console.log(get({ a: [{ b: 1 }] }, "a[0].b", 3)); // output: 1
// 不考虑数组的情况
const _get = (object, keys, val) => {
return keys.split(/\./).reduce(
(o, j)=>( (o || {})[j] ),
object
) || val
}
console.log(get({ a: null }, "a.b.c", 3)); // output: 3
console.log(get({ a: undefined }, "a", 3)); // output: 3
console.log(get({ a: null }, "a", 3)); // output: 3
console.log(get({ a: { b: 1 } }, "a.b", 3)); // output: 1实现 add(1)(2)(3)
function add (a) {
return (b) => {
return (c) => {
return a + b + c
}
}
}
add(1)(2)(3)
// 扩展 :多参数
function addMore (...a) {
let arr = a
return (...b) => {
arr = arr.concat(b)
return (...c) => {
arr = arr.concat(c)
return arr.reduce((i,j) => i+j)
}
}
}
addMore(1)(2,3)(4,5)Promiss实现
// 参数:一个含有异步操作的功能函数。
// 状态管理: Promiss是有三个状态的
// 三要素: resolve,reject,then,
// 链式调用: return this
// 串行
const PENDING = 'pending'
const FULFILLED = 'fulfilled'
const REJECTED = 'rejected'
function MyPromise(execute){
let state = PENDING,
resHandlers = [],
rejHandlers = [],
value = null,
reason = ''
function resolve(val) {
value = val;
state = FULFILLED;
setTimeout(() => {
resHandlers.forEach((headler) => {
headler(val);
})
}, 0);
}
function reject( err ) {
reason = err || '';
state = REJECTED;
setTimeout(() => {
rejHandlers.forEach((headler) => {
headler(reason);
})
}, 0);
}
this.then = ( onFulfilled, onRejected ) => {
if (state === FULFILLED) {
typeof onFulfilled === 'function' && onFulfilled(value)
} else if (this.state === REJECTED) {
typeof onRejected === 'function' && onRejected(reason)
} else {
typeof onFulfilled === 'function' && resHandlers.push(onFulfilled)
typeof onRejected === 'function' && rejHandlers.push(onRejected)
}
return this;
}
execute ( resolve, reject );
}
new MyPromise((resolve) => {
setTimeout(()=> {
resolve('1')
},3000)
}).then((res)=> {
console.log("1",res);
}).then((res)=> {
console.log("2",res);
})
MyPromise.prototype.all = (promisess) => {
return new MyPromise(( resolve, reject ) => {
let resultErr = [],
count = 0;
promisess.forEach((promise,i) => {
promise.then((res) => {
resultErr[i] = res;
if ( ++count === promisess.length ) {
resolve(resultErr)
}
}, (reason) => {
reject(reason)
})
})
})
}手写 发布订阅 (观察者模式)
function MyEventEmiter () {
let eList = [],
index = 0
this.on = (eName, headler) => {
eName && typeof headler === 'function' && eList.push({ index, eName, headler })
index ++;
return this;
}
this.off = (_index) => {
for(var i = 0; i < eList.length ; i++) {
if (eList[i].index === _index) {
eList.splice(i,1);
break;
}
}
}
this.once = (eName, headler) => {
const _index = index;
const _this = this;
eName && typeof headler === 'function' &&
eList.push({
index,
eName,
headler: (data) => {
headler(data);
_this.off(_index);
}
})
index ++;
return this;
}
this.emit = (eName, data) => {
eList.forEach((event) => {
event.eName === eName && event.headler(data);
})
}
}
var myEvent = new MyEventEmiter();
myEvent.once('click', (data) => {
console.log('do click only once', data)
}).on('click', (data) => {
console.log('do click', data)
})
setTimeout(() => { myEvent.emit('click','first'); },100 )
setTimeout(() => { myEvent.emit('click','second'); },100 )
setTimeout(() => { myEvent.emit('click','third'); },100 )数组转树
function arrToTree (arrDate) {
arrDate.forEach((item1) => {
item1.children = arrDate.filter((item2)=>{ return item2.parentId === item1.id})
})
const result = arrDate.filter((a) => { return !a.parentId })
console.log(arrDate)
return result
}
// 网友++转对象,只需遍历一次。
function convert(list) {
const map = list.reduce((acc, item) => {
acc[item.id] = item
return acc
}, {})
const result = []
for (const key in map) {
const item = map[key]
if (item.parentId === 0) {
result.push(item)
} else {
const parent = map[item.parentId]
if (parent) {
parent.children = parent.children || []
parent.children.push(item)
}
}
}
return result
}
arrToTree([
{id:1, parentId: null, name: 'a'},
{id:2, parentId: null, name: 'b'},
{id:3, parentId: 1, name: 'c'},
{id:4, parentId: 2, name: 'd'},
{id:5, parentId: 1, name: 'e'},
{id:6, parentId: 3, name: 'f'},
{id:7, parentId: 4, name: 'g'},
{id:8, parentId: 7, name: 'h'},
]);/*有10个篮子,分别装有1,2,4,8,16,32,64,128,256,512 个苹果,篮子编号为 0 ~ 9,请问如果正好想取 825 个苹果, 需要的篮子编号为多少?例如取 5 个苹果,需要 0,2 号篮子(1 + 4 个)。*/
function getAppleBoxIndex(arr,num) {
const len = arr.length
let res = [];
let cur = 0;
for(let i = len -1; i > -1 ; i--) {
if (cur + arr[i] === num) {
res.push(i);
break;
} else if (cur + arr[i] < num) {
cur += arr[i];
res.push(i);
}
}
return res;
}
getAppleBoxIndex([1,2,4,8,16,32,64,128,256,512],825)
Promise 串行
/**
* 多个Promise 链式依次执行
* 后面promise依赖前面返回的数据
*/
function myCompose(...args){
let prmLink = Promise.resolve();
args.forEach((prm) => {
prmLink = prmLink.then(prm);
})
return prmLink
}
let promA = function() { console.log('promA:acc'); return Promise.resolve(1) };
let promB = function(val) { console.log('promB:acc', val); return Promise.resolve(++val) };
let promC = function(val) { console.log('promC:acc', val); return Promise.resolve(++val) };
let promD = function(val) { console.log('promD:acc', val); return Promise.resolve(++val) };
myCompose(promA,promB,promC,promD).then((val) => {console.log('finally result:', val);});
// promA:acc
// promB:acc 1
// promC:acc 2
// promD:acc 3
// inally result: 4
// Promise {<fulfilled>: undefined}控制promise并行数量
/**
* 控制多个 Promise 异步fetch 同时只能并行执行 limit 个任务
*/
function doFetchList(list, limit) {
const len = list.length;
let result = [];
let count = 0;
return new Promise((resolve, reject)=>{
while(current < limit) {
next();
}
function next() {
let current = count++;
if (current > len) {
resolve(result);
}
fetch(list[current]).then((res) => {
result[current] = res;
if (current < len) next();
},(err) => {
result[current] = err;
if (current < len) next();
})
}
})
}异步请求失败重试
function promiseRetry(asyncFn, maxCount) {
let currentCount = maxCount;
return new Promise((resolve,reject) => {
function run () {
asyncFn().then((res) => {
resolve(res);
},(reason) => {
if (--currentCount) {
run();
} else {
reject(reason)
}
})
}
run();
})
}
//测试用例:
function fn() {
return new Promise((resolve,reject) => {
console.log('running:', new Date());
setTimeout(()=> {
reject('err')
},1000)
})
}
promiseRetry(fn,3).then(() => {
console.log('success');
},(reason) => {
console.log('err:' + reason);
})使用闭包实现每隔 1 秒打印 1-500
// 不用promise
function printNum(maxNum) {
let i = 1
while(i <= maxNum) {
((num) => {
setTimeout(() => {
console.log(num);
}, 1000 * num)
})(i++)
}
}
printNum(500);
// v2:
function printNum(maxNum) {
for(let i = 1; i <= maxNum; ++i) {
((i) => {
setTimeout(() => {
console.log(i);
}, 1000 * i)
})(i)
}
}
printNum(500);
//使用promise
var sleep = function (time, i) {
return new Promise(function (resolve, reject) {
setTimeout(function () {
resolve(i);
}, time);
})
};
var start = async function () {
for (let i = 0; i < 6; i++) {
let result = await sleep(1000, i);
console.log(result);
}
};
start();
返回一个字符串中出现次数最多的字符。
function getMaxlen(str) {
if (!str) return '';
const len = str.length;
if (len <= 1) return str;
let strMap = new Map();
let maxSize = 0;
let result = [];
for (let i = 0; i < len; i++) {
if (strMap.has(str[i])) {
strMap.set(str[i], strMap.get(str[i]) + 1);
maxSize = Math.max(maxSize, strMap.get(str[i]) )
} else {
strMap.set(str[i],1);
}
}
strMap.forEach((value,key) => {
if (value === maxSize) {
result.push(key)
}
})
return result;
}
getMaxlen('abcdccbdb58575') // ["b", "c", "5"]前端工程化
什么是前端工程化
我们都知道,当代前端工程已经从 Page 级别 上升到 App 级别了。并且Web 业务的 复杂化 和 多元化 还在日益提升当中。
这个时候,前端便会面临以下问题:
- 大体量:多功能、多页面、多状态、多系统;
- 大规模:多人甚至多团队合作开发;
- 高性能:
CDN部署、缓存控制、请求合并、按需加载、同步/异步加载、移动端首屏CSS内嵌、HTTP2服务端资源推送。
如果没有 科学 的 管理方法 和 技术手段 的约束。时间,成本会不断上升,代码质量 会不断下降。最后变得难以维护,引发 软件危机 。而 软件工程 便是为了应对 软件危机。
因此,我们也必须以 软件工程 的角度来对待前端开发。来思考以下几个问题:
如何高效的多人协作?
如何提供开发效率?
如何提升开发质量?
如何提升项目可维护性?
如何降低项目生产问题?
软件工程(Software Engineering),简称SE。旨在将系统化的、严格约束的、可量化的方法应用于软件的开发、运行和维护,即将工程化应用于软件。
那么,前端工程化便是运用 软件工程 的 技术 和 方法,让前端开发流程、技术、工具、经验等更加 规范化、标准化。主要目的是为了提高开发效率,提升代码质量,并在项目不断迭代过程中保证 良好的可维护性 和稳定性。
软件工程核心思想
有这样一个公式:SE = 过程 + 方法 + 工具
过程: 解决 软件开发周期 中的 混乱 问题,构建高质量软件。
- 软件开发周期:设计,需求分析,开发,联调,测试,部署,维护,不断迭代。
- 形成 和 规范 开发流程。因地制宜,制定和不断修正,形成适合自己团队的开发流程规范。
方法 : 是指在整个过程中,如何构建系统的方法学。主要手段:
复用:在一个新系统中,大部分的内容是成熟的,只有小部分内容是全新的;复用已有的功能模块,既可以提高开发效率,也可以改善新开发过程中带来的质量问题。
分治:将复杂问题分解为若干可独立解决的简单子问题,并分别独立求解,以降低复杂性;然后再将各子问题的解综合起来,形成最初复杂问题的解。
- 核心问题:怎样的分解策略可以使得软件更容易理解、开发和维护?
折中:不同的需求之间往往存在矛盾与冲突,需要通过折中来作出的合理的取舍,找到使双方均满意的点。
- 核心问题:如何调和矛盾(需求之间、人与人之间、供需双方之间,等等)
演化:软件系统在其生命周期中面临各种变化。要游刃有余的应对这种变化。
- 核心问题:在设计软件的初期,就要充分考虑到未来可能的变化,并采用恰当的设计决策,使软件具有适应变化的能力。
工具: 我们需要工具来辅助方法的执行,提高效率。
- 通过工具,可以把一些手动的工作自动化,比如自动化测试工具,自动构建部署工具;
- 通过工具,可以帮助把一些流程规范起来,比如
Bug跟踪、源代码管理; - 通过工具,帮助提高编码效率,比如各种编辑器
IDE、插件等。
任何简单机械的重复劳动都应该让机器去完成。
前端工程化实践
假设一个前端工程要从 0 开始,我们可以把前端工程化实践分为3个阶段:
- 准备阶段:技术选型;架构设计;业务分治。
- 开发&迭代阶段:如何高效,高质量的进行需求开发,功能迭代。并保证良好的可维护性。
- 部署&维护阶段:自动化打包部署;
CI/CD;生产问题定位;性能优化;
前端是一种技术问题较少、工程问题较多的软件开发领域。
准备阶段
该阶段有三个主要任务:
技术选型:业务场景,公司情况,团队情况三者相结合,选择合适的主框架(比如,
React,Vue),衍生库(如NextJS,AntDesign)以及各类管理工具选择。- 比如,该业务是定制化较强的,面向
C端用户的H5页面;团队成员技术栈以React为主。那么可以选择React主框架,然后规划自己的UI库,工具库,业务组件库等。 - 比如,该业务是
BE后台管理系统,面向内部运营人员。那么可以直接选择阿里开源的AntDesign或者IceWork。自带成熟物料,UI组件库等,可以大大降低开发和维护成本。 - 比如,你的BE后台存在大量的
Form表单操作,可以使用开源的form-render配置化方案来提升开发效率。 - 工具选择:比如代码管理工具,一般是
Git,要制定和严格执行 分支管理策略;包管理器,你可以直接使用npm,推荐yarn。开发工具,主流是VScode,可以选装一系列辅助插件,也可以diy插件。
- 比如,该业务是定制化较强的,面向
架构设计:结合自身业务场景和环境,全面考虑,进行合理的架构设计,即使你使用
IceWork这种自身生态全面的框架。- 比如,对架构进行分层管理,比如设置共享层( 底层UI组件库,公共业务组件库,util工具库等 ),定制层( 功能页面等 )。
业务分治:业务分类,划分子系统;通过单独的
Git仓库进行子系统管理。- 最好建立自己的脚手架工具,子系统通过脚手架统一初始化。
- 权限管理,责任到人。
开发&迭代阶段
前面有提到,这个阶段的主要任务是如何高效,高质量的进行需求开发,功能迭代。并保证良好的可维护性。
目前,我们主要通过以下几个几个方面来进行约束:
- 模块化
- 组件化
- 规范化
模块化:
前端的模块化已经由来已久,已经形成了成熟的进行技术体系。
JS 模块化: 从之前的 RequireJS(AMD)、SeaJS (CMD) 到现在的 CommonJS、ES6 Module。
CSS模块化: 我们还可以使用 Less、Sass、Stylus 等预处理器,对 CSS 进行模块化管理。
资源模块化: Webpack 更是把模块化推向极致,其核心思想是:一切皆模块,除了 JS 和 CSS,还包括 imgage,iconFont 等静态资源。
组件化:
组件化应用了 分治 和 复用 的思想。通过组件化,我们的所有页面都像是通过积木(组件)组合而成。
组件不只包括 UI 组件,还可以是不含 UI 的功能性组件。
组件化追求 小而美。问题是我们在抽象组件的时候,如何达到 小 和 美 的平衡,并不是拆分的越细越好。还有考虑 组件 的 复用性 和 可拓展性。
规范化:
形成一系列规范,并不断完善。严格执行,做好过程管理。
编码规范
组件规范
接口规范
文档规范
规范重要,更重要的规范的执行力度。自觉可能是最重要的,但又是最不可靠的。还是需要一些干预措施:
实行
codeReview。使用
ESlint,Husky,Git hooks等工具约束。
部署&维护阶段
该阶段的核心是 自动化。
首先,前端需要本地 Dev 调试 和 生产打包构建。可以使用 Gulp, Webpack, Babel 等工具库,添加配置文件,编写打包脚本来实现。
Gulp是基于Nodejs的自动任务运行器,它能自动化地完成javascript/sass/less/html/image/css等文件的的测试、检查、合并、压缩、格式化、浏览器自动刷新、部署文件生成,并监听文件在改动后重复指定的这些步骤。优势是利用流的方式进行文件的处理,使用管道(pipe)思想,前一级的输出,直接变成后一级的输入,通过管道将多个任务和操作连接起来,因此只有一次I/O的过程,流程更清晰,更纯粹。Gulp去除了中间文件,只将最后的输出写入磁盘,整个过程因此变得更快。Webpack是一个模块打包工具,它的作用是把 互相依赖 的 模块 处理成 静态资源。其核心思想是一切皆模块。Babel是一个JavaScript编译器。负责把浏览器不认识的语法,编译成浏览器认识的语法。Webpack中可以通过babel-loader使用babel。
可以通过一些 平台 实现 自动化部署 以及 CI/CD。比如 Jenkins,广泛使用的开源CI / CD工具之一。它基于Java,可以自动执行与软件的构建,测试,部署和交付相关的任务。可在Windows,macOS和其他Unix版本上使用。
这些 CI/CD 平台都会用到 容器技术,我们也可以了解一下:
Docker:Docker是一个开源的应用容器引擎,开发者可以打包他们的应用及依赖到一个可移植的容器中,发布到流行的Linux机器上,也可实现虚拟化。kubernetes: 简称k8s, 是一个开源的容器集群管理系统,可以实现容器集群的自动化部署、自动扩缩容、维护等功能。
我们可以用
k8s去管理Docker集群,即可以将Docker看成k8s内部使用的低级别组件。另外,k8s不仅仅支持Docker,还支持Rocket,这是另一种容器技术。